好久没更新博客,最近公司让我出一个代码规范,我吓了一跳。赶忙翻出阿里《 码出高效》,不敢造次,我就补充点个人的想法吧。代码是给人看的。代码风格应该遵循
极简主义

写好代码
- 可维护性(maintainability)
- 所谓的“维护”无外乎就是修改 bug、修改老的代码、添加新的代码之类的工作。所谓“代码易维护”就是指,在不破坏原有代码设计、不引入新的 bug 的情况下,能够快速地修改或者添加代码。
- 可读性(readability)
- 我们在编写代码的时候,时刻要考虑到代码是否易读、易理解。除此之外,代码的可读性在非常大程度上会影响代码的可维护性。
- 可扩展性(extensibility)
- 我们在不修改或少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。说直白点就是,代码预留了一些功能扩展点,你可以把新功能代码,直接插到扩展点上,而不需要因为要添加一个功能而大动干戈,改动大量的原始代码。
- 灵活性(flexibility)
- 灵活性是一个挺抽象的评价标准。如果一段代码易扩展、易复用或者易用,我们都可以称这段代码写得比较灵活。
- 简洁性(simplicity)
- KISS 原则:“Keep It Simple,Stupid”。这个原则说的意思就是,尽量保持代码简单。代码简单、逻辑清晰,也就意味着易读、易维护。我们在编写代码的时候,往往也会把简单、清晰放到首位。
- 可复用性(reusability)
- 代码的可复用性可以简单地理解为,尽量减少重复代码的编写,复用已有的代码。在后面的很多章节中,我们都会经常提到“可复用性”这一代码评价标准。
- 可测试性(testability)
- 代码的可测试性差,比较难写单元测试,那基本上就能说明代码设计得有问题。
避免复杂、追求简单
日常开发中,除了解决业务问题还需要解决许多的工程问题。如何选择当下合适的方法解决问题;需要不断尝试和摸索,没有最好的方法只有更好的方法。
合理平滑的处理技术债务
技术的演变速度太快,如何避免长时间的技术债务是非常严重的问题,总之弊大于利。尽可能保持轻装上阵,避免拖油瓶项目。
关键字:
- 一方库: 本工程内部子项目模块依赖的库(jar 包)。
- 二方库: 公司内部发布到中央仓库,可供公司内部其它应用依赖的库(jar包)。
- 三方库: 公司之外的开源库(jar 包)。
『避免过度封装』
特别是没有完整的技术人员编制的情况下,怎么简单怎么处理(去除中间商赚差价一个道理。)避免过度开发
一方库;建议使用原生方式(综合评估代码量)避免框架过度封装。(Java的方法调用链过长是出了名的恶心)
『避免代码过度重复』
每次开发业务都会写很多的代码。定期对公司项目进行基础代码的重构。合理的拆分
业务无关的基础代码。
『避免版本混乱』
使用统一的版本管理。约束所有的项目jar版本依赖。防止因为过度使用三方库出现奇怪的bug。公司bom需要单独处理。尽量保持与社区版本同步,比如springboot最新版是2.1.3 ,那么公司使用的版本最好是近半年的GA版本。
『物极必反』
请勿过度依赖某框架栈或者解决方式,客观的对比相关解决方案优缺点。
『选择大于努力』
集中精力掌握核心知识。按照目前技术演变的速度,更新最快的是应用技术,其次是行业规范相关技术。最后才是革命性的技术。

指定一种工程结构
统一的工程结构,对开发人员来说如同指路明灯,可以快速的区分相关代码位置。
『阿里巴巴Java开发手册-应用分层』
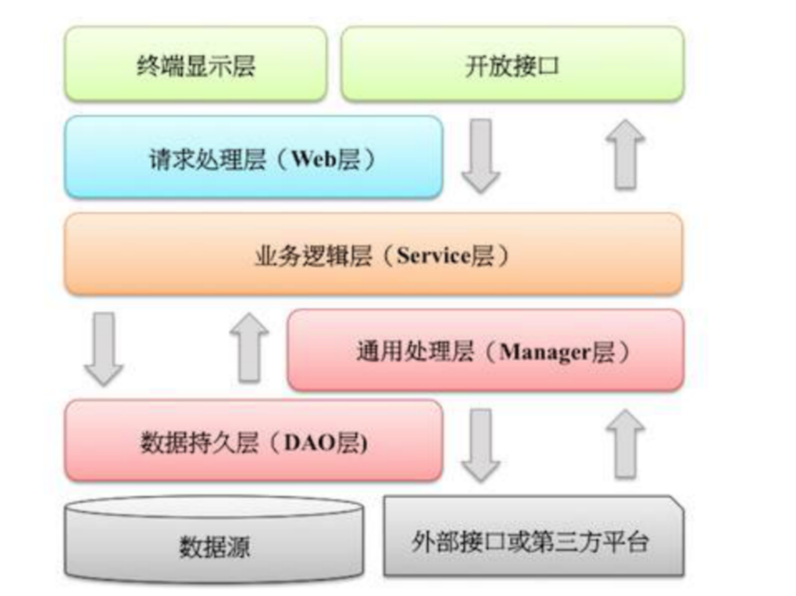
- 开放接口层:可直接封装 Service 方法暴露成 RPC 接口;通过 Web 封装成 http 接口;进行 网关安全控制、流量控制等。
- 终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染, JSP 渲染,移动端展示等。
- Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service 层:相对具体的业务逻辑服务层。
- Manager 层:通用业务处理层,它有如下特征:
- 对第三方平台封装的层,预处理返回结果及转化异常信息;
- 对Service层通用能力的下沉,如缓存方案、中间件通用处理;
- 与DAO层交互,对多个DAO的组合复用。
- DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase 等进行数据交互。
- 外部接口或第三方平台:包括其它部门RPC开放接口,基础平台,其它公司的HTTP接口。
『建议分层方式』
根据工作实际情况,参考阿里的应用分层后适当采纳。
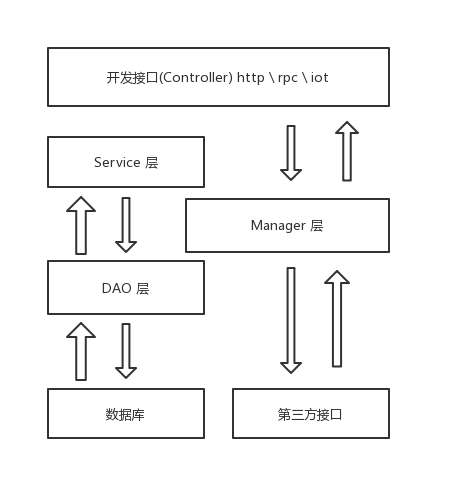
开放接口层:可直接封装 Service 方法暴露成 RPC 接口;通过 Web 封装成 http 接口;进行 网关安全控制、流量控制等。
终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染, JSP 渲染,移动端展示等Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等Service 层:相对具体的业务逻辑服务层。
Manager 层:通用业务处理层,它有如下特征:
对第三方平台封装的层,预处理返回结果及转化异常信息。
对Service层通用能力的下沉,如缓存方案、中间件通用处理。
与DAO层交互,对多个DAO的组合复用。
DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase 等进行数据交互。
外部接口或第三方平台:包括其它部门RPC开放接口,基础平台,其它公司的HTTP接口。
目前Java已经不写前端代码,所以终端显示层和Web已经没有使用的价值。这里需要额外的注意,开放接口层不需要任何的业务操作,方便做完整的单元测试。将参数校验等操作放在具体业务执行的过程中。
『建议分层异常处理方式』
- (分层异常处理规约)在 DAO 层,产生的异常类型有很多,无法用细粒度的异常进行catch,使用catch(Exception e)方式,并throw new xxxException(e),不需要打印日志,因为日志在 Manager/Service 层一定需要捕获并打印到日志文件中去,如果同台服务器再打日志,浪费性能和存储。
在 Service 层出现异常时,必须记录出错日志到磁盘,尽可能带上参数信息,相当于保护案发现场。如果 Manager 层与 Service 同机部署,日志方式与 DAO层处理一致,如果是单独部署,则采用与 Service 一致的处理方式。
『分层领域模型规约』
- DO(Data Object):此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service 或 Manager 向外传输的对象。
- BO(Business Object):业务对象,由 Service 层输出的封装业务逻辑的对象。
AO(ApplicationObject):应用对象,在Web层与Service层之间抽象的复用对象模型, 极为贴近展示层,复用度不高。VO(View Object):显示层对象,通常是 Web 向模板渲染引擎层传输的对象。Query:数据查询对象,各层接收上层的查询请求。注意超过 2 个参数的建议查询封装,禁止使用 Map 类来传输。
没有必要过度设计、导致代码量增加。DTO、AO、VO Query 在实际开发过程实际上可以完全复用。Query是查询参数,通常用于用户分页查询和普通参数查询等封装体。BO需要高度抽象,属于业务模型。目前接口数据显示要求不高的情况可以适当放宽,不使用 BO层。
『分层参考』
- 推荐的参考
主目录示例:com.github.z201.pre
- com.github.z201 公司域名(这只是例子)
- pre 项目名称
- dao 模块名称
模块示例:com.github.z201.pre
- dao #mybaits接口映射层
- entity # mysql表映射层
- dto # 网络传输层
- manger # 第三方(缓存、事务、mp、外部接口)
- service # 主要业务实现(无事务处理、简单业务)
- utils # 项目工具类(该项目独立使用的)
对于该模块关键模块,建议单独区分,用于识别。按照黄金法则,一个模块中核心接口少数。
➜ demo git:(develop) ✗ tree src/main -d -L 7
src/main
├── java
│ └── com
│ └── github
│ └── z201
│ └── pre
│ ├── annotation # 关键业务(注解拦截层)
│ ├── dao # mybaits接口映射层
│ ├── entity # 实体映射层
│ ├── dto
│ │ ├── cache # 缓存传输层
│ │ ├── param # 请求参数封装体(Query的细化)
│ │ ├── result # 响应参数封装体
│ │ └── search # 查询参数封装体(Query的细化)
│ ├── limit # 关键业务实现(关键业务不建议放到service层,方便快速识别。)
│ │ └── impl
│ ├── manger # 第三方(缓存、事务、mp、外部接口)
│ │ └── impl # 实现类
│ ├── service # 主要业务实现(无事务处理)
│ │ └── impl # 实现类
│ └── utils # 项目工具类(该项目独立使用的)
│ └── common
│
└── resource
└── mapper # mybatis文件。
保持代码的整洁
写出运行代码(bug)是简单的、写出适合阅读的代码是困难,建议阅读
阿里巴巴Java开发手册以及码出高效Java开发手册相关章节。这里做下内容补充。
『尽可能少写代码』
写的越多错的越多,错的越多修复越难。
// 使用lombok语法糖,简化模版代码。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class SmSpaceFunctionCache {
/**
* 主键
*/
private Integer id;
/**
* 功能名称
*/
private String name;
/**
* 图片主键id(使用运营后台 sm_admin_pictrue表存储图片)
*/
private Integer adminPictureId;
/**
* 图片地址
*/
private String picPath;
/**
* 排序 默认 0
*/
private Integer orderBy;
// 无 get 、 set 更多特性请查阅lombok使用方法。
}
『提高代码覆盖率』
(避免无调用代码,避免过度使用代码生成器)健壮的代码是干净、简洁的。避免重型项目出现(保持项目业务代码1-2W行,可以适当的模块化)
『合理拆分代码逻辑』
(避免代码过度优化和过早优化,
需求一定会改、一定会改、一定会改)适当调整代码,保证阅读方便即可。推荐使用阿里p3c代码检查工具。鬼故事:李光磊以前劝华为的同事用Eclipse,人家打死不肯用。他自己搞起来,给人家说,你看,多方便。华为的同时默默的输入了一个文件名,跳过去,Eclipse崩贵了,文件太大。
『更新注释』
代码千万行,注释第一行。注释不规范,同事两行泪。改代码不改注释非常容易误导他人。尽可能保持个人代码的注释信息合理。
『面向接口编程』
- 面向接口编程和面向对象编程并不是平级的,它并不是比面向对象编程更先进的一种独立的编程思想,而是附属于面向对象思想体系,属于其一部分。或者说,它是面向对象编程体系中的思想精髓之一。
- 在一个面向对象的系统中,系统的各种功能是由许许多多的不同对象协作完成的。在这种情况下,各个对象内部是如何实现自己的,对系统设计人员来讲就不那么重要了;而各个对象之间的协作关系则成为系统设计的关键。小到不同类之间的通信,大到各模块之间的交互,在系统设计之初都是要着重考虑的,这也是系统设计的主要工作内容。面向接口编程就是指按照这种思想来编程。
- 降低程序的耦合性。在程序中紧密的联系并不是一件好的事情,因为两种事物之间联系越紧密,更换其中之一的难度就越大,扩展功能和debug的难度也就越大。
- 易于程序的扩展。
- 有利于程序的维护。
/**
* 示例代码,在接口暴露层,是不建议做任何的业务操作。建议使用bean封装数据。
**/
@RestController
@RequestMapping(FunctionController.ROUTER_INDEX)
public class FunctionController{
public static final String ROUTER_INDEX = "/api/space";
@Autowired
PackageFunctionServiceI packageFunctionService;
/**
* 获取功能分页列表
* @return
*/
@PostMapping("/function/list")
public Object listSpaceFunction(@RequestBody SpacePackageFunctionSearch pageSearch) {
return packageFunctionService.listSpaceFunction(pageSearch);
}
.....
- if/for/while/switch/do等保留字与左右括号之间都必须加空格。
# 合理的增加空格,方便阅读代码。
if (null == endTime || 0L == endTime) {
throw new RuntimeException("获取用户vip的到期时间失败了,数据出现异常。~~~");
}
防御式编程
- 请不要相信任何参数。尽可能保持客观的态度编写代码。参考<<代码大全>>
『人类都是不安全、不值得信任的,所有的人,都会犯错误,而你写的代码,应该考虑到所有可能发生的错误,让你的程序不会因为他人的错误而发生错误』
// 这是从内部接口调用的数据,首先不信任给的数据。避免常规错误导致自己的逻辑出现明显的bug。
// 获取vip的到期时间
try {
endTime = spaceVipCacheService.getSpaceVipEndTimeByUserId(userId);
} catch (InvalidProtocolBufferException e) {
log.warn("获取用户vip的到期时间失败了,系统出现异常。~~~ ");
throw new RuntimeException("获取用户vip的到期时间失败了,系统出现异常。~~~");
}
if (null == endTime || 0L == endTime) {
log.warn("获取用户vip的到期时间失败了,系统出现异常。~~~ ");
throw new RuntimeException("获取用户vip的到期时间失败了,数据出现异常。~~~");
}
抛异常 or 返回错误码 or 日志
公司外的http/api开放接口必须使用“错误码”;应用内部推荐异常抛出(适当抛出堆栈,性能影响)。避免恶意请求接口,并通过返回消息猜出接口参数的问题。日志文件推荐至少保存15天,因为有些异常具备以“周”为频次发生的特点。
- 就java日志框架而言,建议使用侨接slf4j来输出日志。
- 当遇到问题的时候,只能功过debug功能来确定问题。应该考虑输出日志信息,良好的系统日志信息对问题进行定位的。
- 项目中大量的分支判断if \else、switch 的分支时候使用日志可以定位具体是哪个业务流程。
//尽可能参数化日志信息,日志是给人看的。不是为了输出而输出。关键参数可以隔离显示比如 [{}]
logger.debug("这是一条debug日志 [{}]" , userId);
// 对于debug日志,必须判断日志的级别才能进行输出。
if(logger.isDebugEnabled()){
logger.debug("这是一条debug日志 [{}]" , userId);
}
// 避免使用字符串拼接的方式输出日志,这样会导致生产了很多的string对象。
logger.debug("这是一条字符串拼接的日志输出 : [" + userId +"]");
- 日志级别的使用
日志级别 trace, debug, info, warn, error, fatal
这里以log4j相关的日志的打印级别,OFF即不打印,其他则按照标准级别配置即可,如 debug
关闭:OFF(0)
致命:FATAL(100),对应Logger.fatal方法
错误:ERROR(200),对应Logger.error方法
警告:WARN(300),对应Logger.warn方法
信息:INFO(400),对应Logger.info方法
调试:DEBUG(500),对应Logger.debug方法
跟踪:TRACE(600),对应Logger.trace方法
全部:ALL(Integer.MAX_VALUE)
当指定某一个级别时,比如DEBUG,那么所有低于这个级别的其它级别日志,都会被打印。
当指定级别为DEBUG时,Logger.debug、Logger.info、Logger.warn、Logger.error以及Logger.fatal等方法
都能输出日志,但Logger.trace无法输出日志。
- error:对于影响到程序正常运行的信息,需要及时补货并输出,适用范围
配置文件读取失败、第三方调用失败、数据库连接失败、缓存等关键组件失败异常
方法命名、变量命名
建议阅读
阿里巴巴Java开发手册以及码出高效Java开发手册相关章节。这里做下内容补充。
变量命名
如果想不到合适的变量名字,麻烦把注释写清楚。如果连思考的时间都没有请使用TODO标记。
service层
如果想不到合适的方法名字,麻烦把注释写全。如果连思考的时间都没有请使用TODO标记。
Dao层
如果是批量建议加上Batch。
获取单个对象 `getXxx`
获取多个对象`listXxx`
通过复杂的查询`listXxxBySearch`这里的`search`就是参数封装体
获取统计值 `countXxx`
插入`saveXxx` / `insertXxx`
删除 `removeXxx` / `deleteXxx`
修改 `updateXxx`
Redis
- key名设计
#建议:可读性和可管理性(redis作为标准缓存时推荐)
#以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id
ugc:video:1
#简洁性
#建议:保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:
user:{uid}:friends:messages:{mid}简化为u:{uid}:fr:m:{mid}。
#强制:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
- value设计
# 强制:拒绝bigkey(防止网卡流量、慢查询)
string类型控制在20KB以内,hash、list、set、zset元素个数不要超过5000,这里指的是field(不是key)。
# 反例:一个包含200万个元素的list。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会不出现在慢查询中(latency可查))。
# 建议- 选择适合的数据类型。
例如:实体类型(要合理控制和使用数据结构内存编码优化配置,例如ziplist,但也要注意节省内存和性能之间的平衡)
# 反例
set user:1:name tom
set user:1:age 19
set user:1:favor football
改进
hmset user:1 name tom age 19 favor football
- 控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期),不过期的数据重点关注idletime。
- 【建议】:禁用命令
禁止线上(正式环境)使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
- 【建议】使用批量操作提高效率
原生命令:例如mget、mset。
非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
注意两者不同:
1. 原生是原子操作,pipeline是非原子操作。
2. pipeline可以打包不同的命令,原生做不到。
3. pipeline需要客户端和服务端同时支持。
- 【建议】Redis(伪)事务功能较弱,不建议过多使用
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上(可以使用hashtag功能解决)。
设计原则
抽象、抽象、还是抽象。
- SOLID 原则 -SRP 单一职责原则SOLID 原则
- OCP 开闭原则SOLID 原则
- LSP 里式替换原则SOLID 原则
- ISP 接口隔离原则SOLID 原则
- DIP 依赖倒置原则DRY 原则、KISS 原则、YAGNI 原则、LOD 法则
设计模式
设计模式是针对软件开发中经常遇到的一些设计问题,总结出来的一套解决方案或者设计思路。大部分设计模式要解决的都是代码的可扩展性问题。很多框架都有它们的身影。
| 范围\目的 | 创建型模式 | 结构型模式 | 行为型模式 |
|---|---|---|---|
| 类模式 | 工厂方法 | (类)适配器 | 模板方法、解释器 |
| 对象模式 | 单例 原型 抽象工厂 建造者 | 代理 (对象)适配器 桥接 装饰 外观 享元 组合 | 策略 命令 职责链 状态 观察者 中介者 迭代器 访问者 备忘录 |
GoF的23种设计模式的功能
前面说明了 GoF 的 23 种设计模式的分类,现在对各个模式的功能进行介绍。
- 单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,其拓展是有限多例模式。
- 原型(Prototype)模式:将一个对象作为原型,通过对其进行复制而克隆出多个和原型类似的新实例。
- 工厂方法(Factory Method)模式:定义一个用于创建产品的接口,由子类决定生产什么产品。
- 抽象工厂(AbstractFactory)模式:提供一个创建产品族的接口,其每个子类可以生产一系列相关的产品。
- 建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。
- 代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问。即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。
- 适配器(Adapter)模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
- 桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
- 装饰(Decorator)模式:动态的给对象增加一些职责,即增加其额外的功能。
- 外观(Facade)模式:为多个复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
- 享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。
- 组合(Composite)模式:将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性。
- 模板方法(TemplateMethod)模式:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
- 策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。
- 命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
- 职责链(Chain of Responsibility)模式:把请求从链中的一个对象传到下一个对象,直到请求被响应为止。通过这种方式去除对象之间的耦合。
- 状态(State)模式:允许一个对象在其内部状态发生改变时改变其行为能力。
- 观察者(Observer)模式:多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为。
- 中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解。
- 迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
- 访问者(Visitor)模式:在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式,即每个元素有多个访问者对象访问。
- 备忘录(Memento)模式:在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它。
- 解释器(Interpreter)模式:提供如何定义语言的文法,以及对语言句子的解释方法,即解释器。
编程规范
对于编码规范,考虑到很多书籍已经讲得很好了(比如《重构》《代码大全》《代码整洁之道》等
代码重构
在软件开发中,只要软件在不停地迭代,就没有一劳永逸的设计。随着需求的变化,代码的不停堆砌。