前言
增加生产力设备,记录下系统开发环境过程。
环境安装流程
1 | setup 1 安装brew |
Brew
第一步:在Mac上安装Brew
- 由于国内安装会超时,因此推荐使用国内开源项目中的安装方式。
1 | https://gitee.com/cunkai/HomebrewCN?_from=gitee_search |
- 执行脚本安装即可
常用命令
1 | # 更新 |
Wget、Curl
- 使用brew 安装下载工具便于后续安装程序
1 | brew install wget |
增加生产力设备,记录下系统开发环境过程。
1 | setup 1 安装brew |
1 | https://gitee.com/cunkai/HomebrewCN?_from=gitee_search |
1 | # 更新 |
1 | brew install wget |
财报的全称是财务报告,包括财务报表及附注说明,不仅仅是财务情况的披露,更能体现一个公司的整体经营情况及行业价值链网。


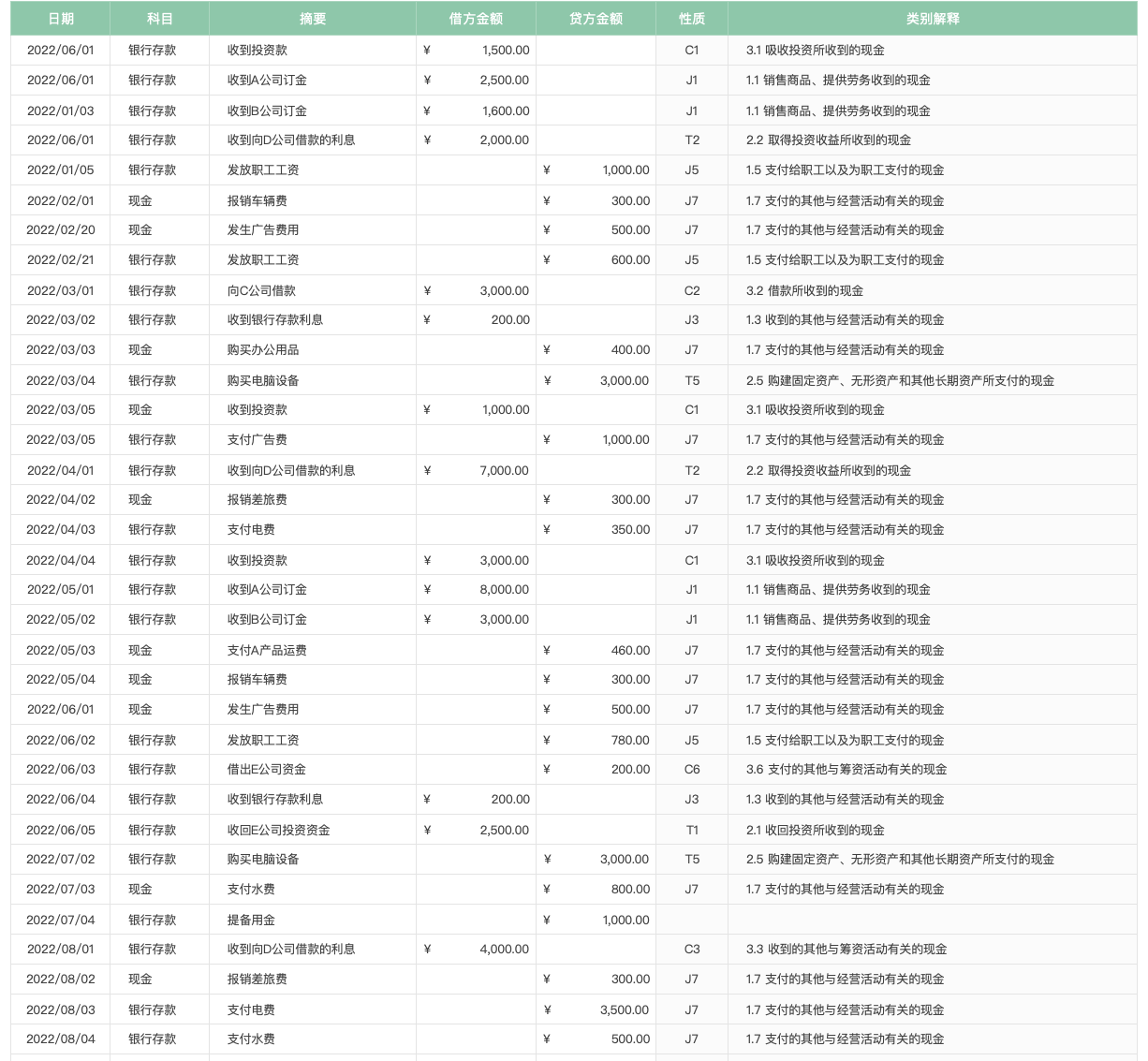
凡在本期内实际收到或付出的一切款项,无论其发生时间早晚或是否应该由本期承担,均作为本期的收益和费用处理。
简单解释:只有收到钱了才确认记账,不管这笔交易实际上是发生在哪个周期。
单式记账法和复式记账法是两种不同的记账方法。
这条等式被称为会计恒等式,是一切会计对应关系和核算的基础。在我们的日常观念中,这一条等式其实是很反人类的,为什么资产会由负债组成?

其实举一个简单的栗子就可以理解,正如贷款购房,房产总价 1000 万,我首付 400 万,剩余 600 万我贷款,那么在这个场景中,我已经购买了房子,1000 万就是我的资产,但这又不完全都是我自己的,只有 400 万才真正是我自己的,剩下的 600 万其实是我的负债,我还需要把负债还清了,因此,所有者权益又被称为净资产。

记账方式就是把复式记账法+ 会计恒等式结合在一起,并写出会计的分录,举一些的例子:

用现金花了100 块买衣服:
用花呗花了 100块买衣服:
用花呗花了10块钱吃饭:
「借」反映的是资产的增加、负债和所有者权益的减少,而「贷」反映的是资产的减少、负债和所有者权益的增加。
1970年,诺贝尔经济学奖得主弗里德曼(Friedman)提出“企业从事旨在提高利润的活动”,这种“股东至上”主义在很长一段时间被认为是美国企业的使命。1997年,由美国近200家最著名企业的首席执行官组成的协会——商业圆桌会议(Business Round Table,以下简称BRT),他们这样定义企业的使命(Mission):管理层和董事会的首要职责是对企业股东负责,而其他利益相关者是对股东责任的派生物。
2019年8月19日,BRT 发布了一份新的企业使命宣言,其中强调企业要“为客户创造价值、投资于员工、公平且合乎道德地与供应商打交道、支持我们的社区、保护环境”。这样的使命宣言,更加强调企业的社会责任(Social Responsibility),即企业股东利益最大化可以,但是有条件。
由此得出企业存在的意义就是盈利,通过各类经济活动获得利润,并向股东分红;同时为了扩大经营,又会不断获取新的投资。
财务是一个很泛的概念,可理解为跟公司资金流动相关的一切活动及关系,按照财务管理的定义,一般会包括筹资、投资、日常管理及利润分配四部分。公司里只要是跟钱相关的,都需要有财务的介入,而当业务进行到一定体量时,财务会深入业务流程以控制成本、提高收益率,同时财务还会负责公司的经营风险评估和控制,影响公司的经营决策。
国内“注册会计师”的六大学科。
常见的财务活动如,财务规划、收入核算、总账与报表、固定资产管理、员工薪酬、税务等
一家集团型公司尤其是上市公司,其财务核算、财报编制、财务管理、税务管理、经营内控等制度要求都是非常严格、标准和精细化的。当一家公司的财务信息化建设到达一定规模时,其财务管理相关的IT投入会逐渐发生边际成本递减,而这一切成本集约化的前提,便是构建一套符合公司业务场景、流程的现状与未来,能够准确进行数据输出并辅助管理决策的自研财务产品体系。
正常情况下,业务系统通常只会记录流水,正确的记录业务流水。通过会计账单引擎进行转换,转换成财务需要的凭证格式。

幸得领导信任,负责BOI项目资料整理申报;第一次做跨国项目申报,资料多次修改后最终申请通过,历经4个月申请排队;终于在2023-04得到BOI批准。
相关企业连续8年企业所得税减免,可购买泰国土地。
与其他国家/地区相比,有很多泰国和外国投资者更注重在泰国做生意。因为泰国有很多优势,无论是气候,地理资源,位子适合作为东盟的中心。尤其是陆上,水上和空中的运输,有很多专业的劳动力,具有数量和质量潜力的农业原料,有各种各样的农产品,例如:大米,橡胶,甘蔗,蔬菜和新鲜水果。所有这些都足以为投资者创造利润和回报。因此,政府建立了投资促进计划(BOI),以支持和鼓励希望在泰国做生意的投资者,并为外国投资者增加投资的吸引力。
其实,将公司进入BOI并不困难,但是需要仔细和周到地准备文件,检查业务是否符合BOI设定的条件,
如果完全符合BOI的要求,并且文件完整则可以申请。向BOI请求支持将帮助您会获得各种好处,对您的业务对有利。
| 种类 | 行业类别 | 例子业务 |
|---|---|---|
| 1 | 农业及农产品加工业 | 生产加工淀粉、生产医疗食品、生物肥料等. |
| 2 | 矿物、陶瓷和基础金属 | 矿产勘探、生产玻璃或陶瓷制品、生产钢铁上中下游业务等 |
| 3 | 轻工业 | 生产医疗器械或零件、生产家具、生产玩具、生产纺织品等 |
| 4 | 金属产品、机械设备和运输工具 | 机械制造、配件、发动机、交通工具部件、摩托车等 |
| 5 | 电子与电器业 | 生产电器及部件、硬盘驱动器、微电子物质、数码科技等 |
| 6 | 化工产品、塑料及造纸 | 药品、印刷品、工业化工产品、塑胶包装制品、纸制品等 |
| 7 | 服务业和公用事业 | 公用行业和基本服务、大众货物运输业务、医疗服务、旅游业等 |
| 8 | 发展科技创新 | 发展生物技术、纳米技术、先进材料、数字技术等 |
故障永远只是表面现象,其背后技术和管理上的问题才是根因。技术和管理上的问题,积累到一定量通过故障的形式爆发出来,所以故障是现象,是在给我们严重提醒。在日常运营中,无论什么原因,产品出现服务中断、服务品质下降,导致用户体验下降的情况,都称为故障(故障不包括用户方环境引发的场景)。



故障管理任务分解
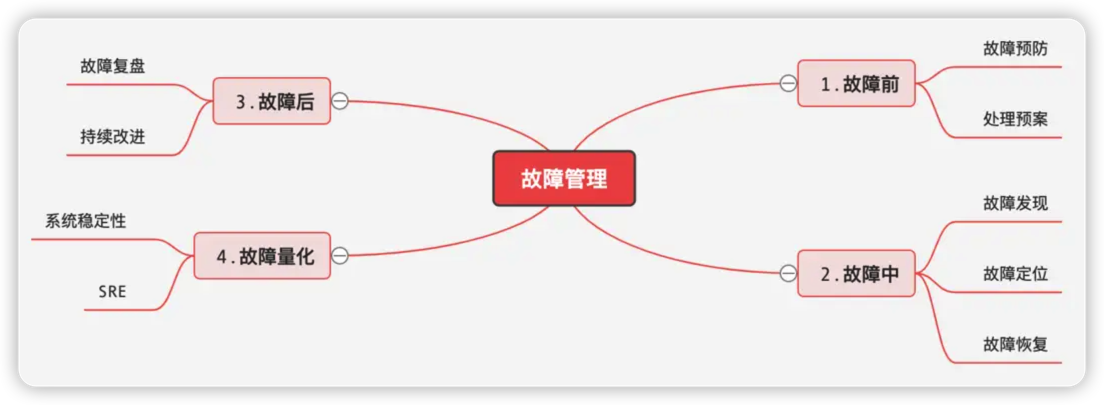
提前达成共识,上线运营前的问题统一称为bug,上线运营后的问题统一称为故障&事故。


第一原则:优先恢复业务,而不是定位问题。(在故障组处理的第一原则优先考虑恢复方案)
故障应急流程由故障应急小组来主导。对外同步信息,包括大致原因,影响面和预估恢复时长,同时屏蔽各方对故障处理人员的干扰;对内组织协调各团队相关人员集中处理。
故障发生后,一定要严肃对待。大多数情况下,会过渡盯着故障本身,而揪着相关责任人不放。进而形成一些负面影响。为此将注意力转到故障背后的技术和处理更为合适。
复盘的目的是为了从故障中学习,找到我们技术和管理上的不足,然后不断改进。
主要针对故障发生时间点,故障影响面,恢复时长,主要处理人或团队做简要说明。
故障处理时间线回顾。技术支持在故障处理过程中会简要记录处理过程,这个过程要求客观真实即可。业务恢复后,与处理人进行核对和补充。这个时间线的作用非常关键,它可以相对真实地再现整个故障处理过程。
确定相关故障原因,故障根因的改进措施进行讨论;就事论事。
故障完结统计,故障完结报告的主要内容包括故障详细信息,如时间点、影响面、时间线、根因、责任团队(这里不暴露责任人)、后续改进措施,以及通过本次故障总结出来的共性问题和建议。这样做的主要目的是保证信息透明,同时引以为戒,期望团队也能够查漏补缺,不要犯同样的错误。
定责的过程是找出跟因,针对不足找出改进措施。落实责任到人。定责的目标,是责任到人。并且让团队成员意识到自己的不足。对故障处理的坚决态度。
高压线,类似酒后不开车,
对于明知高压线依然触犯导致故障需要处罚。
无论是理论还是实践,均证明故障只要有发生的可能,它总会发生。所以为了保障业务稳定性,需提前发现、解决风险,及时发现、定位原因、快速恢复故障,同时要确保改进措施有效落地、避免故障重复发生,我们需要建立一个规范可遵循、闭环的故障管理体系。
Site Reliability Engineer 目前仅实施小部分关键内容,完成最小MVP。SRE-稳定性目标
| 系统可用性 | 故障时间/年 | 故障时间/月 | 故障时间/周 | 故障时间/日 |
|---|---|---|---|---|
| 90% | 36.5天 | 72小时 | 16.8小时 | 2.4小时 |
| 99% | 3.65天 | 7.2小时 | 1.68小时 | 14.4分 |
| 99.9% | 8.76小时 | 43.8分钟 | 10.1分钟 | 1.44分 |
| 99.99% | 52.56分钟 | 4.38分钟 | 1.01分钟 | 8.66秒 |
| 99.999% | 5.26分钟 | 25.9秒 | 6.05秒 | 0.86秒 |
NOC(Network Operation Center)或者叫技术支持 ,这个角色主要有两个职责:一是跟踪线上故障处理和组织故障复盘,二是制定故障定级定责标准,同时有权对故障做出定级和定责。
要提高系统的稳定性,就要制定衡量系统稳定性的相关指标,系统的稳定性指标主要有以下两个:
核心目标
SRE体系建设-可用性建设
近期在处理公司项目历史债务问题,由于客观历史原因导致。为了快速收益初期不知情况下产生。定期不清理债务导致。
根据当前情况,除重写策略以外,其他策略同时进行。按阶段将债务问题逐步偿还。根据阶段性成果适当调整下个阶段的重点工作。
技术债务和贷款买房的思维模式一样,如果借技术债务的收益大于利息的时候,大胆借!
策略并没有绝对好坏,需要根据当前项目场景灵活选择。有个简单原则可以帮助你选择,那就是看哪一种策略投入产出ROI更好。
防止技术债务产生的主要方法是了解开发团队存在的技术债务。开发团队必须全面了解技术债务,以及债务对项目的影响。合适的流程可以帮助开发团队避免技术债务积累,例如代码、设计、架构和测试的审查等。而且,这些流程必须是务实的,否则事与愿违。
经过90天的努力,体重最大相差20KG。按照月均计算,已经减重15KG。
已经造成了生活上的不便利,几年前精神旺盛,白天都不困。最近一年中午吃完饭就犯困。
旅游容易暴饮暴食是真的。
2021-11月初在苏州旅游的时候,因为体重原因不让玩水上项目。
2021-11月11日我把床头坐塌了,我突然意识到问题的严重性了。
2021-11月11日买了体脂秤,各项指标显示我的身体已经不非常不健康了,开始了减重。

体重已经下降很多了,下一步是就是健康。体脂率下降主要减少脂肪。
尝试下使用python Matplotlib可视化数据。

1 | ➜ jupyter-example git:(main) python --version |
尝试下使用python可视化数据。

1 | ➜ jupyter-example git:(main) python --version |
RediSearch 是一个高性能的全文搜索引擎,它可以作为一个 Redis Module(扩展模块)运行在 Redis 服务器上。

1 | mkdir -p redisearch/data |
1 | ➜ docker-run redis-cli |
1 | 127.0.0.1:6379> FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]" |
简单优化的下博客。
hexo 默认生成文章命名方式,在中文标题下很不友好。可以选择生成永久的链接。
1 | npm install hexo-abbrlink --save |
1 | #permalink: :year/:month/:day/:title/ |
1 | crc16 & hex |
编写第一个CLI小程序练手。
1 | cargo new learning-05 |
1 | reqwest = { version = "0.11", features = ["blocking"]} |
1 | use std::fs; |
1 | url https://z201.vip output z201.md |
1 | use std::fs; |
1 | ➜ learning-05 git:(master) ✗ cargo run https://z201.vip z201.md |
1 | reqwest = { version = "0.11", features = ["blocking"]} |
1 | use std::fs; |
1 | cargo build --release |
1 | cd target/release |
Rust的核心功能之一 ownership ,运行的程序都需要使用计算机管理内存的方式,比如Java 具备垃圾回收,还有一些语言需要手动去释放内存。而Rust则是第三种方式,通过所有权管理内存,编译器在编译时会根据一些列规则检查,在运行时所有权系统的任务功能都不会减慢程序。
栈是程序运行的基础。每当一个函数被调用时,一块连续的内存就会在栈顶被分配出来,这块内存被称为帧(frame)。
栈以放入值的顺序存储并以相反的顺序取出值。这也被称为 后进先出 (last in , first out) 。添加数据的时候加 进栈 (pushing anto the stack) ,而移出数据叫 出栈 (poping off th stack)。
在调用的过程中,一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当这个函数调用结束,通过副本,可以恢复出原本的寄存器的上下文,就像什么都没有经历一样。此外,函数所需要使用到的局部变量,也都会在帧分配的时候被预留出来。
栈的操作时非常快的,这主要得益于它存取数据的方式,数据的存取位置总时在栈顶,而不需要重新寻找一个位置去存放或者读取。另一个属性就是,栈中所有的数据都必须占据已知且固定的大小。
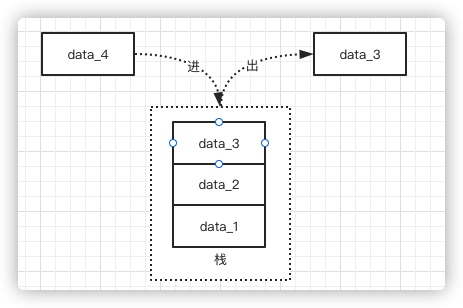
在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。
1 | fn say(name : String){ |
tomcat 和 jetty,当say方法执行的时候才知道参数的具体长度。1 | let mut arr = Vec::new(); |
如果手工管理堆内存的话,堆上内存分配后忘记释放,就会造成内存泄漏。一旦有内存泄漏,程序运行得越久,就越吃内存,最终会因为占满内存而被操作系统终止运行。
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能发生使用已释放内存(use after free)的情况。
函数遍布于 Rust 代码中,Rust 代码中的函数和变量名使用 snake case 规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。
fn 开始并在函数名后跟一对圆括号。大括号告诉编译器哪里是函数体的开始和结尾。1 | fn main() { |
1 | Hello, world! |
函数也可以被定义为拥有 参数(parameters),参数是特殊变量,是函数签名的一部分。当函数拥有参数(形参)时,可以为这些参数提供具体的值(实参)。
1 | fn number(x:i8){ |
1 | Hello, world! |
x的参数,x的类型被指定为i8。Rust 是一种静态类型的语言。 Rust 中的每个值都是某种数据类型。 编译器可以根据分配给它的值自动推断变量的数据类型。
使用let关键字声明变量
1 | fn main() { |
1 | Rust基础语法! |
学习下Rust
在知乎上看到一个人对Rust的评论。
首先,Rust 是有点反人类,否则不会一直都不火。然后,Rust 之所以反人类,是因为人类这玩意既愚蠢,又自大,破事还贼多。 你看 C++ 就很相信人类,它要求人类自己把自己 new 出来的东西给 delete 掉。 C++:“这点小事我相信你可以的!” 人类:“没问题!包在我身上!” 然后呢,内存泄漏、double free、野指针满世界飘…… C++:“……”
Java 选择不相信人类,但替人类把事办好。 Java:“别动,让我来,我有gc!” 人类:“你怎么做事这么慢呀?你怎么还 stop the world 了呀?你是不是不爱我了呀?” Java:“……”
Rust 发现唯一的办法就是既不相信人类,也不惯着人类。 Rust:“按老子说的做,不做就不编译!” 人类:“你反人类!” Rust:“滚!”
权限管理是一个几乎所有大中型 B 端系统都会涉及的重要组成部分,其目的是对整个系统进行权限控制,避免造成误操作及数据泄露等风险问题。
权限相关的基本概念:
抽象来看权限体系可以分为如下两类:功能权限 与 数据权限 两部分。
jvm调优是日常工作中经常会使用的技巧,整理下。
为什么要调优,当默认配置参数不能很好的发挥程序性能的时候。
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。
- 延迟:GC低停顿和GC低频率。
- 低内存占用。
- 高吞吐量。
- 堆内存 = Old + Eden + S0 + S1
- 年轻的 = Eden(新生代) + S0 + S1
- 标准参数(-),所有JVM都必须支持这些参数的功能,而且向后兼容
- 非标准参数(-X),默认JVM实现这些参数的功能,但是并不保证所有JVM实现都满足,且不保证向后兼容。
- 非稳定参数(-XX),此类参数各个JVM实现会有所不同,将来可能会不被支持,需要慎重使用。
1 | -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio=8 -XX:+UseConcMarkSweepGC |
1 | -XX:MetaspaceSize=128m (元空间默认大小) |
1 | java -XX:+PrintFlagsFinal -XX:+UnlockDiagnosticVMOptions -version | wc -l |
建议 -Xms = 最大内存 * [0.6. ~0.8] 这里需要考虑系统损耗内存、和实际物理内存。
堆内存与堆外内存
必须是1024的倍数,且不能低于2M。
32位机器,最大1G/4G 64位机器最大可以超过 32G/64G
堆外内存一般指 Direct Memory ,不受GC控制,JVM、Netty都可能使用堆外内存。
1 | -XX:MaxDirectMemorySize 限制 |
首先我们需要理解java是如何运行的,为什么需要java虚拟机?
我们常用方式一般是安装java运行环境(jre)用命令行的方式启动或者直接双击jar运行。jre包含的java运行的必要环境。
Java 作为一门高级程序语言,它的语法非常复杂,抽象程度也很高。编译出来的也不是机器可以直接直接运行代码。所以使用面向Java语言的虚拟机运行Java编译以后的特定代码。这里的特定代码指的是Java字节指令码。
1 | -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/log/heap.log |
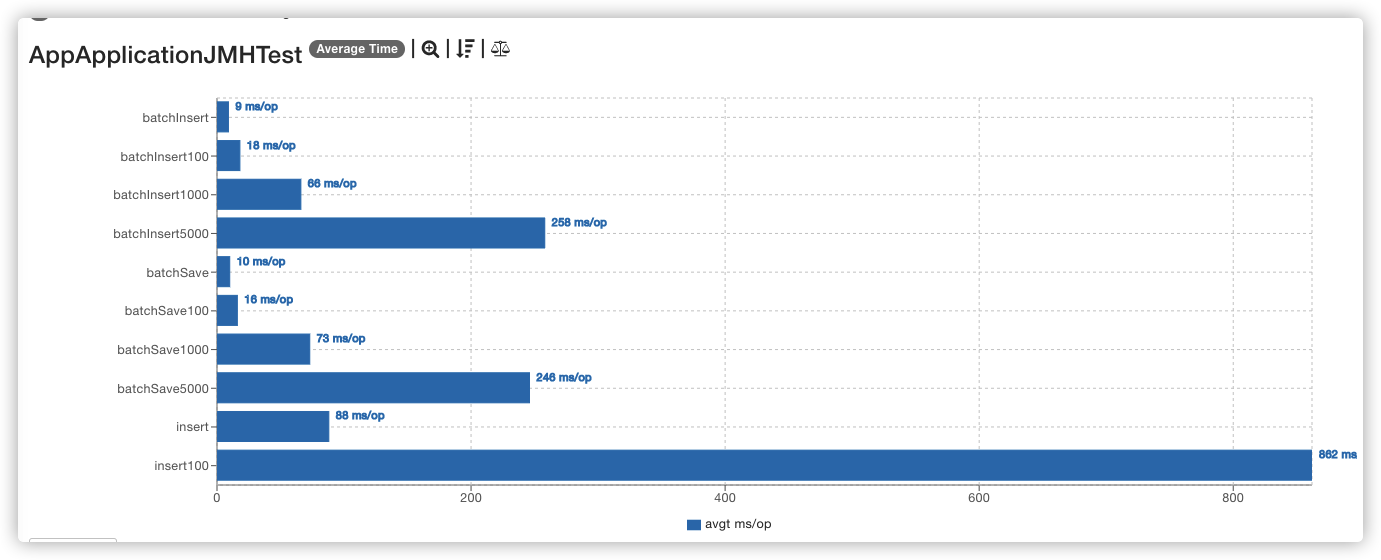
开发过程中经常会出现批量写入数据库的操作,特别是后台系统,在导入数据的场景下会对表性能造成一定影响。
SQL插入主要使用INSERT语句,有两种常见的用法。
1 | INSERT INTO `table_data` ('field1','field2') VALUES ('data1','data2'); |
1 | INSERT INTO `table_data` ('field1','field2') VALUES ('data1','data2'),('data1','data2'); |
插入数据有两种实现,foreach、batchExecutor。
1 | <insert id="batchInsert"> |
1 |
|
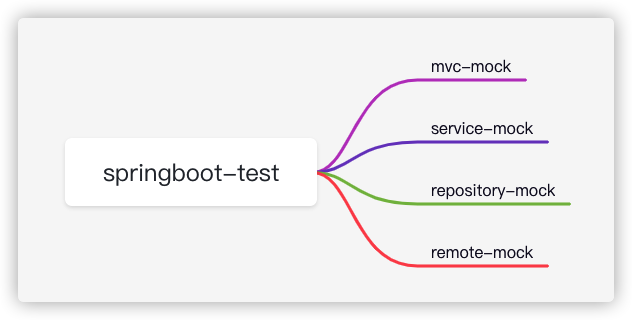
mock
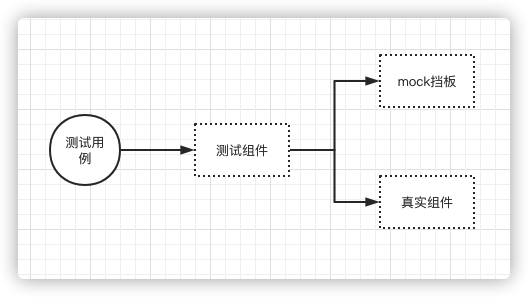
mvc-mock 测试Controller
service-mock 测试 Service
repository-mock 测试 Data
remote-mock 测试 远程接口
Spring Test & Spring Boot Test:为 Spring 和 Spring Boot 框架提供的测试工具。
1 | [INFO] +- org.springframework.boot:spring-boot-starter-test:jar:2.4.5:test |
Redis 中不能直接使用布隆过滤器,Redis 4.0 版本之后提供的 modules(扩展模块)
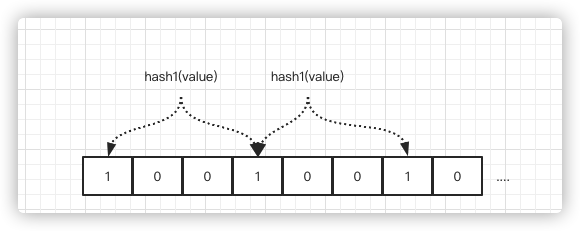
1 | k≈0.7*(m/n) |
演示情况直接使用docker来安装,免去下载编译过程。
1 | docker run -p 6379:6379 -d redislabs/rebloom:latest |
1 | ➜ docker-run redis-cli |
记录最近在Centos7上面部署jenkens。安装的方法有很多,下面采用最简单的方式安装。
jenkins 是一个协调者的身份,管理和协调了代码库,代码仓库,代码运行环境等。
Jenkins是一个开源软件项目,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。持续集成(CI)已成为当前许多软件开发团队在整个软件开发生命周期内侧重于保证代码质量的常见做法。它是一种实践,旨在缓和和稳固软件的构建过程。并且能够帮助您的开发团队应对如下挑战:


