故障管理
故障永远只是表面现象,其背后技术和管理上的问题才是根因。技术和管理上的问题,积累到一定量通过故障的形式爆发出来,所以故障是现象,是在给我们严重提醒。在日常运营中,无论什么原因,产品出现服务中断、服务品质下降,导致用户体验下降的情况,都称为故障(故障不包括用户方环境引发的场景)。
- 在日常运营中,无论什么原因,产品出现服务中断、服务品质下降,导致用户体验下降的情况,都称为故障(故障不包括用户方环境引发的场景)。
- 为什么会频繁出故障?
- 为什么一个小问题或者某个部件失效,会导致全站宕机or服务不可用?
- 为什么发生了故障没法快速知道并且快速恢复?
故障管理规划
- 紧急联系人清单:建立一份紧急联系人清单,列出技术团队成员、管理层、供应商以及其他关键利益相关者的联系信息。确保所有人都知道如何联系到这些人,并在必要时可以迅速响应。
- 故障分类与级别划分:建立一份故障分类与级别划分表,将故障划分为不同的级别,例如紧急、高、中、低等级别。定义每个级别的响应时间和解决时间,以及分配给哪些人员和团队进行处理。
- 值班制度:建立一份值班制度,确保团队可以在任何时间响应故障。值班制度应该包含轮值制度、联系人信息、响应流程和注意事项等方面的细节。
- 故障报告和跟踪:建立一份故障报告和跟踪系统,以便团队可以及时记录故障、跟踪解决进度、追踪根本原因,并确保所有人都可以访问这些信息。故障报告和跟踪系统可以是一个内部的工具,也可以是一个第三方工具,如Jira或ServiceNow等。
- 预防措施和持续改进:故障管理不仅仅是应急响应,还需要预防措施和持续改进。团队应该分析故障原因,识别重复出现的故障,并采取措施防止它们再次发生。同时,团队应该不断优化流程,提高响应速度和解决效率。
- 培训和知识共享:建立一份培训和知识共享计划,确保团队成员具备必要的技能和知识。团队应该定期组织培训,分享最佳实践和经验,并建立一个知识库,以便所有人都可以访问有用的信息。
产研故障等级划分
- 一级故障P0:一级故障是指对业务或客户产生严重影响的故障,例如系统崩溃、数据丢失或业务无法正常运行等。一级故障需要立即处理,必须由最高级别的技术人员或高管介入处理,并且立即解决。
- 二级故障P1:二级故障是指对业务或客户产生较大影响的故障,例如某些业务功能无法使用或性能下降等。二级故障需要及时处理,由具备高级别技术经验的人员处理,并且需要在30分钟内解决。
- 三级故障P2:三级故障是指对业务或客户产生轻微影响的故障,例如某些功能无法正常使用,但业务可以继续运行等。三级故障需要尽快处理,由具备相关技术经验的人员处理,并且需要在2个小时内解决。
- 四级故障P3:四级故障是指对业务或客户影响不大的故障,例如某些功能异常或提示信息错误等。四级故障需要在合理时间内解决,由具备基本技术经验的人员处理,并且需要在8个小时内解决。
- 五级故障P4:五级故障是指对业务或客户影响较小的故障,例如一些次要功能无法使用或界面样式问题等。五级故障需要在适当的时间内解决,由具备一定技术知识的人员处理,并且需要在8个小时内解决。
产研故障来源分类
- 系统故障分类
- 基础设施故障:互联网公司的基础设施包括服务器、网络、存储、数据库等,故障可能会导致系统宕机、数据丢失等问题。这些故障通常需要进行设备维护、系统监控、灾备恢复等方式进行处理。
- 软件故障:软件故障是指由于软件设计缺陷、编码错误、系统兼容性问题等原因引起的故障。
- 集成错误:包括系统集成错误、组件集成错误等。这些错误通常是由于研发人员在系统或组件集成过程中出现的错误导致的,需要通过集成测试、回归测试等方式进行检查和修正。
- 性能问题:包括系统性能问题、代码性能问题等。这些问题通常是由于研发人员在编写代码或设计系统时未考虑到性能因素导致的,需要通过性能测试、优化等方式进行检查和修正。
- 安全问题:包括系统安全问题、数据安全问题等。这些问题通常是由于研发人员在设计或编写代码时未考虑到安全因素导致的,需要通过安全测试、漏洞扫描等方式进行检查和修正。
- 用户体验问题:包括界面设计不当、功能不完善等。这些问题通常是由于软件设计或编写时未考虑到用户需求导致的,需要通过用户反馈、用户调研等方式进行检查和修正。
- 界面故障问题:包括用户界面显示不正常、功能按钮无法点击、菜单无法弹出等问题。这类故障通常与用户交互相关,需要进行UI调试和界面优化。
- 功能故障问题:包括软件功能无法正常使用、程序崩溃、功能异常等问题。这类故障通常需要进行代码调试和功能重构。
- 人为因素:人为因素是指由于员工的失误、操作不当、意外或恶意行为等原因引起的故障。
- 编码和文档错误:包括代码错误、文档错误等。这些错误通常是由于研发人员在编写代码或文档时出现的错误导致的,需要通过代码审查、文档审查等方式进行检查和修正。
- 系统配置错误:包括系统配置错误、环境配置错误等。这些错误通常是由于研发人员在系统配置或环境配置时出现的错误导致的,需要通过系统配置检查、环境配置检查等方式进行检查和修正。
- 环境因素:环境因素是指由于自然灾害、供电故障、通信中断、网络异常等外部因素引起的故障。
- 第三方服务故障:第三方服务故障是指由于供应商服务故障、维护计划、升级等原因引起的故障。
- 时间分类:白天故障、夜晚故障、周末故障。
- 来源分类:用户报告、自动化告警、监视系统等。
故障来源

故障生命周期

故障生命周期流程

故障管理任务
故障管理任务分解
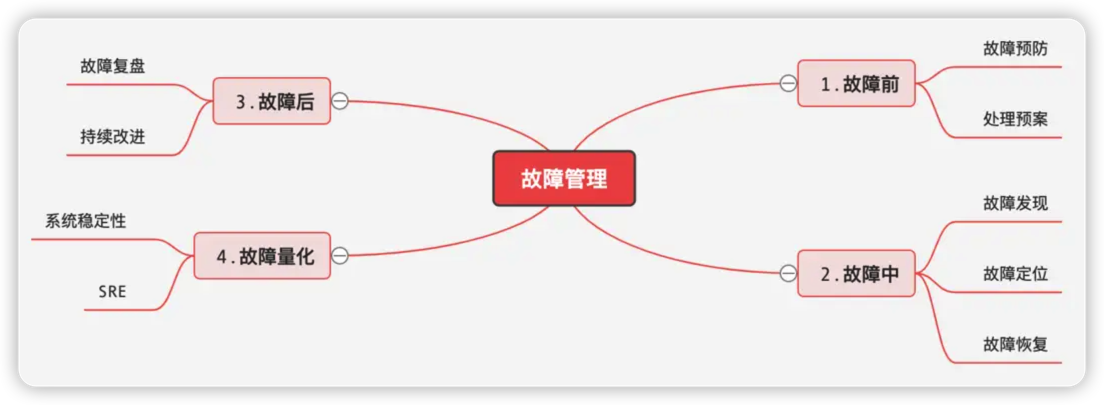
故障前
提前达成共识,上线运营前的问题统一称为bug,上线运营后的问题统一称为故障&事故。
故障预防

产研故障预防流程

处理预案
第一原则:优先恢复业务,而不是定位问题。(在故障组处理的第一原则优先考虑恢复方案)
- 业务恢复预案
- 信息通报(工单登记、邮件通知技术团队)。完成上述第一步后,通常会给相关技术和业务团队通报故障初步信息,包括登记、影响面、故障简述以及主要处理团队。
- 确定故障影响面及等级。故障会通过监控、告警、业务反馈或用户投诉几个渠道反馈过来,这时技术支持会根据故障定级标准,快速做出初步判断,确认影响面,以及故障等级。
- 组织故障会议。对于无法马上恢复或仍需要定位排查的故障,根据问题紧急程度就近处理。
- 恢复系统预案
- 重启;大多情况下适用多数情况,但是重启后容易出现脏数据。
- 回滚;回滚的条件是,故障与最近发布有关。
- 降级;暂停出问题的模块,需要与业务方沟通,暂时离线出问题的模块。
- 限流、扩容;如果是系统扛不住业务流量,可以选择扩容服务。如果不能扩容,可以选择限流,按照一定百分比的流量限流。
故障中
故障应急流程由故障应急小组来主导。对外同步信息,包括大致原因,影响面和预估恢复时长,同时屏蔽各方对故障处理人员的干扰;对内组织协调各团队相关人员集中处理。
故障发现
- 确认故障的有效性,登记故障缺陷。同步故障信息给对应的技术团队。
故障定位
故障发生后,一定要严肃对待。大多数情况下,会过渡盯着故障本身,而揪着相关责任人不放。进而形成一些负面影响。为此将注意力转到故障背后的技术和处理更为合适。
- 评估大致原因,影响面和预估恢复时长。组织应急小组处理故障。
- 在大多数情况下故障定级别都是在处理环境评估,为了提高整体效率,在需求评审和技术评审阶段就应该完成相关业务故障所带来的故障风险。将工作前置化处理,降低运营阶段处理周期。
- 如果使用到了第三方的服务,如公有云的各类服务,包括 IaaS、PaaS、CDN 以及视频等等,原则就是默认第三方无责。
故障恢复
- 确定故障处理方案
- 包括:正常业务流程处理提交数据修改 / 修改配置 / 回滚 / 紧急版本发布
- 协调推进故障处理
- 避免扯皮推诿。避免争执不清,甚至出现诋毁攻击的情况。
- 正视问题,严肃对待。找出自身不足,作为改进的主要责任者,来落地或推进改进措施。
- 客户沟通
- 与客户保持联系,
故障后
故障复盘
复盘的目的是为了从故障中学习,找到我们技术和管理上的不足,然后不断改进。
主要针对故障发生时间点,故障影响面,恢复时长,主要处理人或团队做简要说明。
故障处理时间线回顾。技术支持在故障处理过程中会简要记录处理过程,这个过程要求客观真实即可。业务恢复后,与处理人进行核对和补充。这个时间线的作用非常关键,它可以相对真实地再现整个故障处理过程。
确定相关故障原因,故障根因的改进措施进行讨论;就事论事。
- 第一问:故障原因有哪些?
- 第二问:如何避免再出出现类似故障?
- 第三问:当时恢复业务方式?
- 第四问:当前系统中是否存在类似的潜在风险?
故障完结统计,故障完结报告的主要内容包括故障详细信息,如时间点、影响面、时间线、根因、责任团队(这里不暴露责任人)、后续改进措施,以及通过本次故障总结出来的共性问题和建议。这样做的主要目的是保证信息透明,同时引以为戒,期望团队也能够查漏补缺,不要犯同样的错误。
定责的过程是找出跟因,针对不足找出改进措施。落实责任到人。定责的目标,是责任到人。并且让团队成员意识到自己的不足。对故障处理的坚决态度。
高压线,类似酒后不开车,
对于明知高压线依然触犯导致故障需要处罚。
- 未经技术主管授权,私自变更线上代码和配置。
- 未经技术主管授权,私自在业务高峰期进行网络配置变更。
- 未经技术主管授权,私自在生产环境调试。
- 未经技术主管授权,私自变更生产数据信息。
- 未经技术主管授权,私自将未验证代码合并至主分支。
持续改进
无论是理论还是实践,均证明故障只要有发生的可能,它总会发生。所以为了保障业务稳定性,需提前发现、解决风险,及时发现、定位原因、快速恢复故障,同时要确保改进措施有效落地、避免故障重复发生,我们需要建立一个规范可遵循、闭环的故障管理体系。
- 改进措施:基于复盘信息制定可验的证改进措施,完成时间点,负责人。如果改进措施无效,故障还会重复发生。
故障量化
SRE
Site Reliability Engineer 目前仅实施小部分关键内容,完成最小MVP。SRE-稳定性目标
- 尽量减少系统故障或异常运行状态的发生,提升系统可用的运行时间占比。
- 这里需要考虑三个因素:成本因素、业务容忍度、系统稳定程度。
| 系统可用性 | 故障时间/年 | 故障时间/月 | 故障时间/周 | 故障时间/日 |
|---|---|---|---|---|
| 90% | 36.5天 | 72小时 | 16.8小时 | 2.4小时 |
| 99% | 3.65天 | 7.2小时 | 1.68小时 | 14.4分 |
| 99.9% | 8.76小时 | 43.8分钟 | 10.1分钟 | 1.44分 |
| 99.99% | 52.56分钟 | 4.38分钟 | 1.01分钟 | 8.66秒 |
| 99.999% | 5.26分钟 | 25.9秒 | 6.05秒 | 0.86秒 |
NOC(Network Operation Center)或者叫技术支持 ,这个角色主要有两个职责:一是跟踪线上故障处理和组织故障复盘,二是制定故障定级定责标准,同时有权对故障做出定级和定责。
要提高系统的稳定性,就要制定衡量系统稳定性的相关指标,系统的稳定性指标主要有以下两个:
- MTBF,Mean Time Between Failure,平均故障时间间隔。
- MTTR,Mean Time To Repair, 故障平均修复时间。
- MTTI(Mean Time To Identify,平均故障发现时间;故障发现,故障发生到响应)
- MTTK(Mean Time To Know,平均故障认知时间;故障定位,根因或是根因范围定位出来为止)
- MTTF(Mean Time To Failure,平均失效前时间;故障恢复,采取措施恢复业务)
- MTTV(Mean Time To Verify,平均故障修复验证时间;故障恢复验证,故障解决后验证业务恢复所用时间)
核心目标
- 提升 MTBF,也就是减少故障发生次数,提升故障发生间隔时长。
- 降低 MTTR,故障不可避免,那就提升故障处理效率,减少故障影响时长。
SLI
SRE体系建设-可用性建设
- 容量(Volume):服务承诺的最大容量是多少,从QPS、TPS、流量、连接数、吞吐量;
- 可用性(Availability):服务是否正常,看HTTP状态码2xx的占比;
- 延迟(Latency):服务响应速度是否够快,rt是否在预期范围内;
- 错误率(Errors):错误率有多少,看HTTP状态码5xx的占比;
- 人工介入(Tickets):是否需要人工介入处理,考虑人工修复。