开发过程中经常会出现批量写入数据库的操作,特别是后台系统,在导入数据的场景下会对表性能造成一定影响。
Mybatis-ONE-SQL
SQL插入主要使用INSERT语句,有两种常见的用法。
逐条插入
- 如果插入的记录过多,比如大于20条记录,性能损耗非常严重。
INSERT INTO `table_data` ('field1','field2') VALUES ('data1','data2');
批量插入
- 在日常开发中使用最多的方式,但是数量大比如大于100条的时候插入性能非常差。
INSERT INTO `table_data` ('field1','field2') VALUES ('data1','data2'),('data1','data2');
Mybatis-Foreach-SQL
插入数据有两种实现,foreach、batchExecutor。
<insert id="batchInsert">
INSERT INTO `table_data`(`create_time`)
VALUES
<foreach collection="tableDataList" item="item" index="index" separator=",">
(#{item.createTime})
</foreach>
</insert>
Mybatis-Batch-SQL
- 配合foreach执行
@Component
@Slf4j
public class BatchDao {
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
public <T,M> boolean batchSave(Collection<T> entityList, Class<M> mapper, BiConsumer<M,Collection<T>> fuc) {
SqlSessionFactory sqlSessionFactory = sqlSessionTemplate.getSqlSessionFactory();
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
M entityMapper = sqlSession.getMapper(mapper);
try {
fuc.accept(entityMapper, entityList);
sqlSession.flushStatements();
sqlSession.clearCache();
return true;
} catch (Exception e) {
log.error("{}",e.getMessage());
sqlSession.rollback();
} finally {
sqlSession.close();
}
return false;
}
}
测试结果
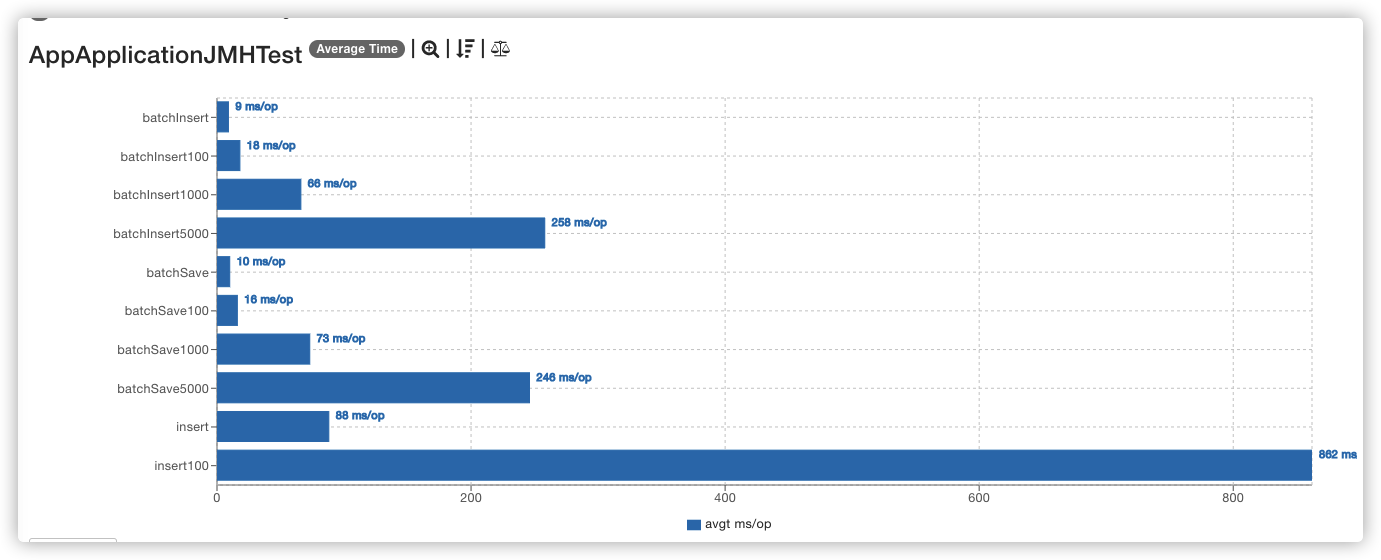
- 10条数据 foreach > batch > insert
- 100条数据 foreach > batch > insert
- 1000条数据 foreach > batch > insert
- 5000条数据 batch > foreach (数据量大,batch优势就出来了)
测试代码
/**
* @author z201.coding@gmail.com
**/
@Slf4j
@State(Scope.Benchmark)
public class AppApplicationJMHTest {
private final static Integer MEASUREMENT_ITERATIONS = 1;
private final static Integer WARMUP_ITERATIONS = 1;
static ConfigurableApplicationContext context;
protected TableDataDao tableDataDao;
protected BatchDao batchDao;
protected SqlSessionFactory sqlSessionFactory;
@Setup(Level.Trial)
public synchronized void initialize() {
try {
String args = "";
if (context == null) {
context = SpringApplication.run(AppApplication.class, args);
}
tableDataDao = context.getBean(TableDataDao.class);
batchDao = context.getBean(BatchDao.class);
sqlSessionFactory = context.getBean(SqlSessionFactory.class);
tableDataDao.truncate();
} catch (Exception e) {
e.printStackTrace();
}
}
// Throughput 整体吞吐量,例如”1秒内可以执行多少次调用”。
// AverageTime: 调用的平均时间,例如”每次调用平均耗时xxx毫秒”。
// SampleTime: 随机取样,最后输出取样结果的分布,例如”99%的调用在xxx毫秒以内,99.99%的调用在xxx毫秒以内”
// SingleShotTime: 以上模式都是默认一次 iteration 是 1s,唯有 SingleShotTime 是只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
// All(“all”, “All benchmark modes”);
@Test
public void executeJmhRunner() throws RunnerException {
Options opt = new OptionsBuilder()
// 设置类名正则表达式基准为搜索当前类
.include("\\." + AppApplicationJMHTest.class.getSimpleName() + "\\.")
// 都是一些基本的参数,可以根据具体情况调整。一般比较重的东西可以进行大量的测试,放到服务器上运行。
.warmupIterations(WARMUP_ITERATIONS) // 多少次预热
.measurementIterations(MEASUREMENT_ITERATIONS) // 要做多少次测量m
.timeUnit(TimeUnit.MILLISECONDS) // 毫秒
// 不使用多线程
.forks(0) // 进行 fork 的次数。如果 fork 数是2的话,则 JMH 会 fork 出两个进程来进行测试。
.threads(1) // 每个进程中的测试线程,这个非常好理解,根据具体情况选择,一般为cpu乘以2。
.mode(Mode.AverageTime)
.shouldDoGC(true)
.shouldFailOnError(true)
.resultFormat(ResultFormatType.JSON) // 输出格式化
.result("/dev/null") // set this to a valid filename if you want reports
// .result("benchmark.json")
.shouldFailOnError(true)
.jvmArgs("-server")
.build();
new Runner(opt).run();
}
private List<TableData> mockData(int size) {
List<TableData> list = new ArrayList<>();
Long time = Clock.systemDefaultZone().millis();
for (int i = 0; i < size; i++) {
list.add(TableData.builder().createTime(time + i).build());
}
return list;
}
@Benchmark
public void insert() {
List<TableData> tableDataList = mockData(10);
tableDataList.stream().forEach(i -> tableDataDao.insert(i));
}
@Benchmark
public void batchInsert() {
List<TableData> tableDataList = mockData(10);
tableDataDao.batchInsert(tableDataList);
}
@Benchmark
public void batchSave() {
List<TableData> tableDataList = mockData(10);
boolean result = batchDao.batchSave(tableDataList, TableDataDao.class, (mapper, data) -> {
mapper.batchInsert(tableDataList);
});
}
@Benchmark
public void insert100() {
List<TableData> tableDataList = mockData(100);
tableDataList.stream().forEach(i -> tableDataDao.insert(i));
}
@Benchmark
public void batchInsert100() {
List<TableData> tableDataList = mockData(100);
tableDataDao.batchInsert(tableDataList);
}
@Benchmark
public void batchSave100() {
List<TableData> tableDataList = mockData(100);
boolean result = batchDao.batchSave(tableDataList, TableDataDao.class, (mapper, data) -> {
mapper.batchInsert(tableDataList);
});
}
@Benchmark
public void insert1000() {
List<TableData> tableDataList = mockData(1000);
tableDataList.stream().forEach(i -> tableDataDao.insert(i));
}
@Benchmark
public void batchInsert1000() {
List<TableData> tableDataList = mockData(1000);
tableDataDao.batchInsert(tableDataList);
}
@Benchmark
public void batchSave1000() {
List<TableData> tableDataList = mockData(1000);
boolean result = batchDao.batchSave(tableDataList, TableDataDao.class, (mapper, data) -> {
mapper.batchInsert(tableDataList);
});
}
@Benchmark
public void batchInsert5000() {
List<TableData> tableDataList = mockData(5000);
tableDataDao.batchInsert(tableDataList);
}
@Benchmark
public void batchSave5000() {
List<TableData> tableDataList = mockData(5000);
boolean result = batchDao.batchSave(tableDataList, TableDataDao.class, (mapper, data) -> {
mapper.batchInsert(tableDataList);
});
}
}