Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,开发团队就开始用 Cassandra 和 sharded MySQL 替代原有的系统。然而和 MySQL 不同的是,Cassandra 没有内置为每一条数据生成唯一 ID 的功能,因为在一个分布式环境下,很难有完美的 ID 生成方案。
对于 Twitter 而言,这样的 ID 生成方案要满足两个基本的要求,一是每秒能生成几十万条 ID 用于标识不同的 tweet;二是这些 ID 应该可以有个大致的顺序,也就是说发布时间相近的两条 tweet,它们的 ID 也应当相近,这样才能方便各种客户端对 tweet 进行排序。
第一个要求意味着 ID 生成要以一种非协作的(uncoordinated)的方式进行,例如不能有一个全局的原子变量。
第二个要求使得 tweet 按 ID 排序后满足 k-sorted 条件。如果序列 A 要满足 k-sorted,当且仅当对于任意的 p, q,如果 1 <= p <= q - k (1 <= p <= q <= n),则有 A[p] <= A[q]。换句话说,如果元素 p 排在 q 前面,且相差至少 k 个位置,那么 p 必然小于或等于 q。如果 tweet 序列满足这个条件,要获取第 r 条 tweet 之后的消息,只要从第 r - k 条开始查找即可。
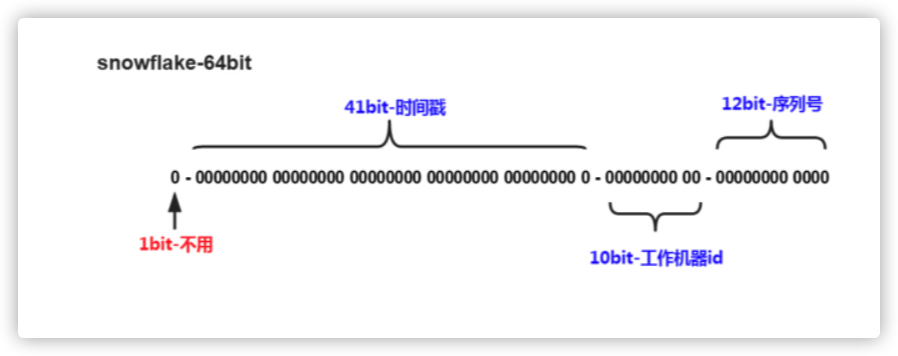
Twitter 解决这两个问题的方案非常简单高效:每一个 ID 都是 64 位数字,由时间戳、节点号和序列编号组成。其中序列编号是每个节点本地生成的序号,而节点号则由 ZooKeeper 维护。
# JMH version: 1.21 # VM version: JDK 1.8.0_275, OpenJDK 64-Bit Server VM, 25.275-b01 # VM invoker: /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home/jre/bin/java # VM options: -server # Warmup: 1 iterations, 10 s each # Measurement: 1 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: cn.z201.jmh.AppApplicationTest.environment # Run progress: 0.00% complete, ETA 00:00:20 # Fork: N/A, test runs in the host VM # *** WARNING: Non-forked runs may silently omit JVM options, mess up profilers, disable compiler hints, etc. *** # *** WARNING: Use non-forked runs only for debugging purposes, not for actual performance runs. *** # Warmup Iteration 1: .____ _ __ _ _ /\\/ ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) '|____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: SpringBoot :: (v2.4.5)
[cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][StartupInfoLogger.java : 55] Starting application using Java 1.8.0_275 on z201MacBook-Pro.local with PID 23242 (started by zengqingfeng in /Users/zengqingfeng/word/code-example/SpringBoot-JMH) [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][SpringApplication.java : 679] The following profiles are active: dev [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][Bootstrap.java : 68] UT026010: Buffer pool was not set on WebSocketDeploymentInfo, the default pool will be used [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][ServletContextImpl.java : 371] Initializing Spring embedded WebApplicationContext [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][ServletWebServerApplicationContext.java : 289] Root WebApplicationContext: initialization completed in 809 ms [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][ExecutorConfigurationSupport.java : 181] Initializing ExecutorService 'applicationTaskExecutor' [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][Undertow.java : 120] starting server: Undertow - 2.2.7.Final [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][Xnio.java : 95] XNIO version 3.8.0.Final [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][NioXnio.java : 59] XNIO NIO Implementation Version 3.8.0.Final [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][Version.java : 52] JBoss Threads version 3.1.0.Final [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][UndertowWebServer.java : 133] Undertow started on port(s) 9031 (http) [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][StartupInfoLogger.java : 61] Started application in 2.018 seconds (JVM running for 3.629) [cn.z201.jmh.AppApplicationTest.environment-jmh-worker-1][AppApplicationTest.java : 40] dev
The capture session could not be initiated on interface ‘en0’ (You don’t have permission to capture on that device). Please check to make sure you have sufficient permissions… 大概提示这么一句话
解决方法有两种
1
sudo chmod 777 /dev/bpf*
或者
1
sudo chown 你的电脑用户名:admin bp*
修改完成后检查
1
ls -la | grep bp
如果没有生效,重启试试。
快速使用
选中一个设备比如WIFI:en0
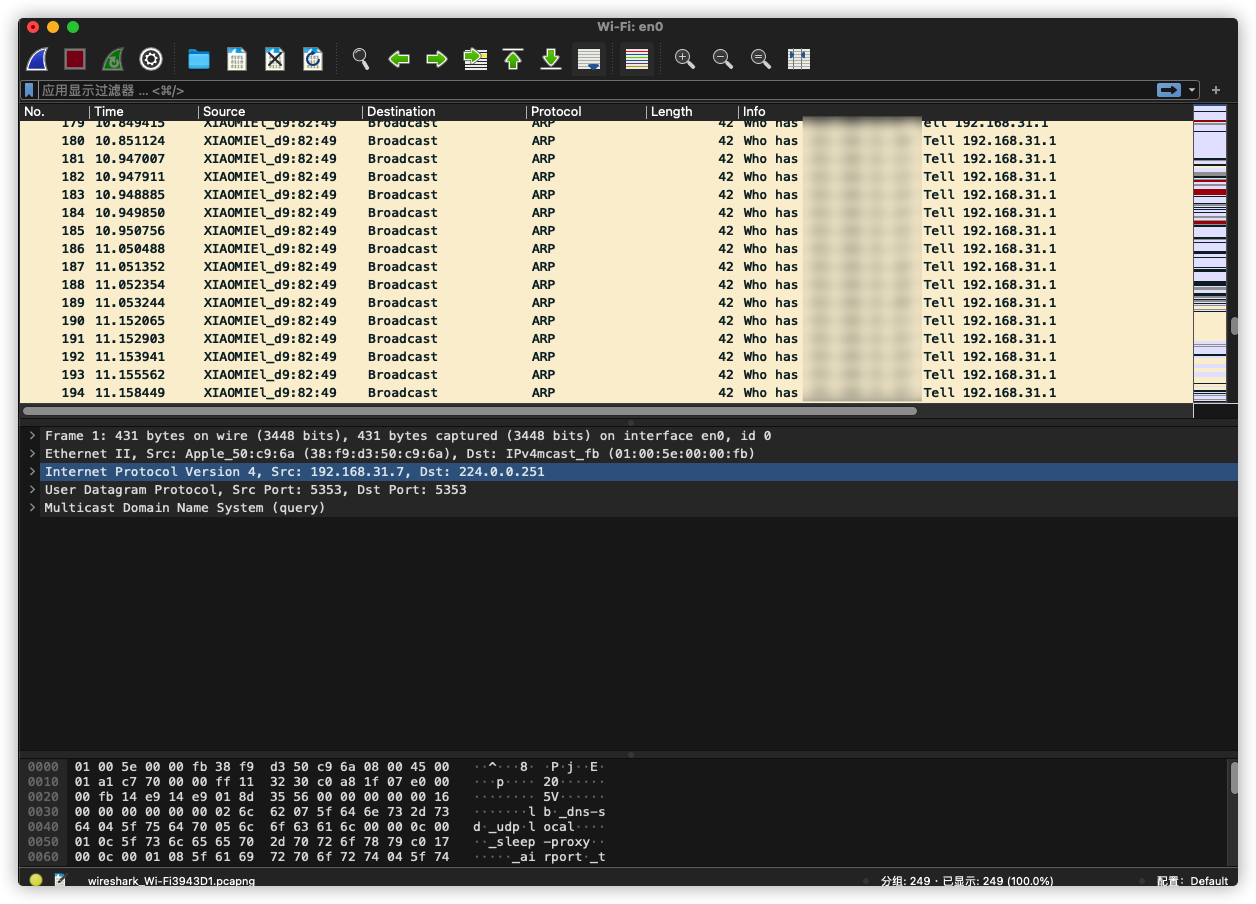
上图显示连接到我了的小米wifi。
界面介绍
需要我们注意到地方
Display Filter(显示过滤器), 用于过滤。
Packet List Pane(封包列表), 显示捕获到的封包, 有源地址和目标地址,端口号。 颜色不同,代表Packet Details Pane(封包详细信息), 显示封包中的字段。
# JMH version: 1.21 # VM version: JDK 1.8.0_275, OpenJDK 64-Bit Server VM, 25.275-b01 # VM invoker: /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home/jre/bin/java # VM options: -server # Warmup: 1 iterations, 10 s each # Measurement: 1 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 8 threads, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: cn.z201.jmh.ListBenchmark.testArrayList # Parameters: (size = 100)