本章是整理知识内容,为强化知识长期更新。
Java集合
集合是Java提供的工具包、包含常用的数据结构:集合、链表、队列、栈、数组、映射等。Collection的包是java.util.*。
Collection

Map

实际上还有Cloneable、Serializable接口是都集合类需要实现的,通用所以不不画上去了。
Java集合主要划分4个部分:
- List(列队)
- Set(集合)
- Map(映射)
- 工具类(Iterator迭代器、Enumeration枚举类、Arrays、Collections)
划重点
- Conllection
- List
ArrayListVector- Stack
LinkedList
- Set
HashSetTreeSetLinkedHashSet
- Queue
- List
- Map
HashMapHashTableTreeMap
- 工具
- Arrays
- Collections
- Enumeration
Java类库中具体集合
| 集合类型 | 概括 |
|---|---|
| ArrayList |
一种可以动态增长和缩减的索引序列,访问速度很快但是插入和删除比ArrayList慢。 |
| LinkedList |
一种可以在任何位置进行高效地插入和删除操作的有序序列,但是访问比较ArrayList慢。 |
| CopyOnWriteArrayList |
CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口,支持高并发。 |
| ArrayDeque |
一种循环数组实现的双端序列。 |
| HashSet |
一种没有重复元素的无序集合。 |
| TreeSet |
一种有序集合。 |
| EnumSet<E extends Enum |
一种包含枚举类型的集合。 |
| LinkedHashSet |
一种可以记住元素插入顺序的集合。 |
| PriorityQueue |
一种允许高效删除最小元素的集合。 |
| HashMap<K , V> | 一个存储 键 / 值 关联的数据结构。 |
| TreeMap<K , V> | 一种键值有序排列的映射表。 |
| EnumMap<K extends Enum |
一种键属于枚举类型的映射表。 |
| LinkedHashMap<K ,V > | 一种可以记住键 / 值 项添加顺序的映射表。 |
| WeakHashMap<K , V > | 一种其值无用武之地后可以被垃圾回收回收的映射表。 |
| IdentityHashMap<K , V> | 一种用 == 而不是用用 equals 比较的映射表。 |
Java Collection Interface
Set
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
List
- ArrayList:基于动态数组实现,支持随机访问。
- Vector:和 ArrayList 类似,但它是线程安全的。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
Queue
- LinkedList:可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
- ConcurrentHashMap:并发线程安全的hashMap。
泛型E
该接口封装了不同类型的结合,使得开发人员操作集合的时候不必关心他们具体的实现,核心的集合接口是Java集合框架的基础。证如上图看到的核心集合接口的层次关系。
Interface
首先简单的介绍下接口以及接口的方法,便于后面的深入学习。
Iterator
Iterable
Collection
Queue
- LinkedList 双向列队结构。
- PriorityQueue 基于堆机构实现,可以用来做优先级列队。
Set
- HashSet 基于哈希实现,支持快速查找,但不支持有序性操作,例如根据一个范围查找元素的操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- TreeSet 基于红黑树实现,支持有序性操作,但是查找效率不如 HashSet,HashSet 查找时间复杂度为 O(1),TreeSet 则为 O(logN);
LinkedHashSet 具有 HashSet 的查找效率,且内部使用链表维护元素的插入顺序。
List
- ArrayList 基于动态数组实现,支持随机访问元素。
- Vector 和ArrayList类似,但是它是线程安全的。
- Stack 是Vector的子类,它实现了一个标准的后进先出的栈。
- LinkedList 基于双向循环列表,只能顺序访问;可以快速的插入和删除元素。而且,LinkedList还可以用作栈、列队和双端列队。
Map<K , V >
需要特别说明下Irertor<E> 和Iterable<T>这两个接口,Iterator模式是用于遍历集合类的标准方法。它主要用于将 访问逻辑从不同的类型集合类中抽象出来、所以在很多实现了Iterble集合类中实现这个多个Iterator接口。这样避免向客用户包撸集合内部的结构,这就是为什么我们用的这么爽的原因之一。
实现类一览表
| Collction | 排序 | 随机访问 | Key-Value | 可重复元素 | 空元素 | 线程安全 |
|---|---|---|---|---|---|---|
| ArrayList | Y | Y | N | Y | Y | N |
| LinkedList | Y | N | N | Y | Y | N |
| HashSet | N | N | N | N | Y | N |
| TreeSet | Y | N | N | N | N | N |
| HashMap | N | Y | Y | N | Y | N |
| TreeMap | Y | Y | Y | N | N | N |
| Vector | Y | Y | N | Y | Y | Y |
| Stack | Y | N | N | Y | Y | Y |
| Hashtable | N | Y | Y | N | N | Y |
| Properties | Y | N | N | Y | Y | Y |
| CopyOnWriteArrayList | Y | Y | Y | N | N | Y |
| ConcurrentHashMap | N | Y | Y | N | N | Y |
| CopyOnWriteArrayList | N | N | N | N | Y | Y |
Iterator 接口
- 迭代器必须从属容器、其作用就是迭代所属容器中的元素。源代码看出这是一个泛型接口。就是迭代泛型类元素。
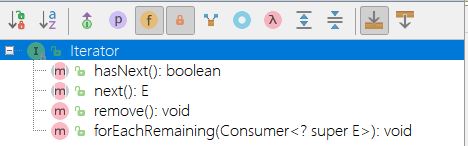
1 | public interface Iterator<E> { |
Iterable 接口
- 这个接口被Collection继承。
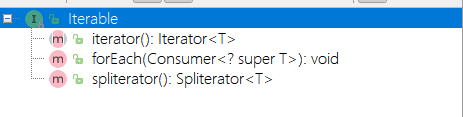
1 | public interface Iterable<T> { |
Collection 接口
- 这个接口集合接口。
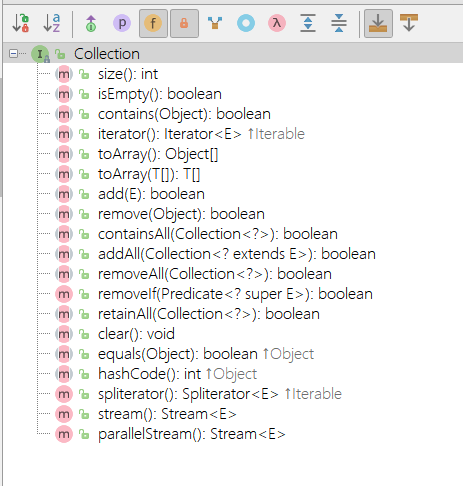
1 | public interface Collection<E> extends Iterable<E> { |
Map 接口
翻译成中文就是地图,x y 坐标代表地图上的一个位置。Map就是一种 键\值的存在。键好比地图中的x y ,值好比地图中的位置。
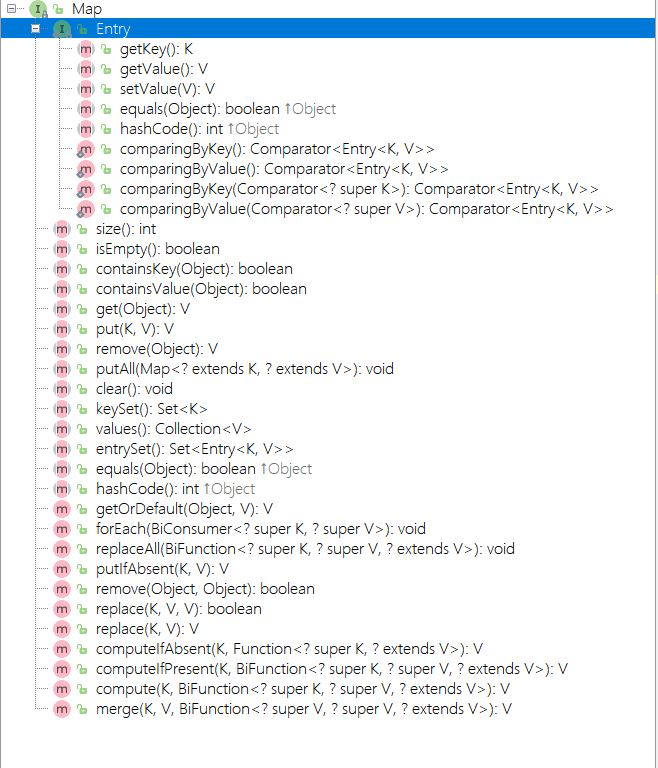
1 | public interface Map<K,V> { |
对比下Vector、ArrayList、LinkedList之前有何区别。
Vector

- Vector是Java早期提供的线程安全动态数组,和ArrayList之间在扩容方面有很多的区别,Vector是扩容2倍,而ArrayList扩容1.5倍。
ArrayList
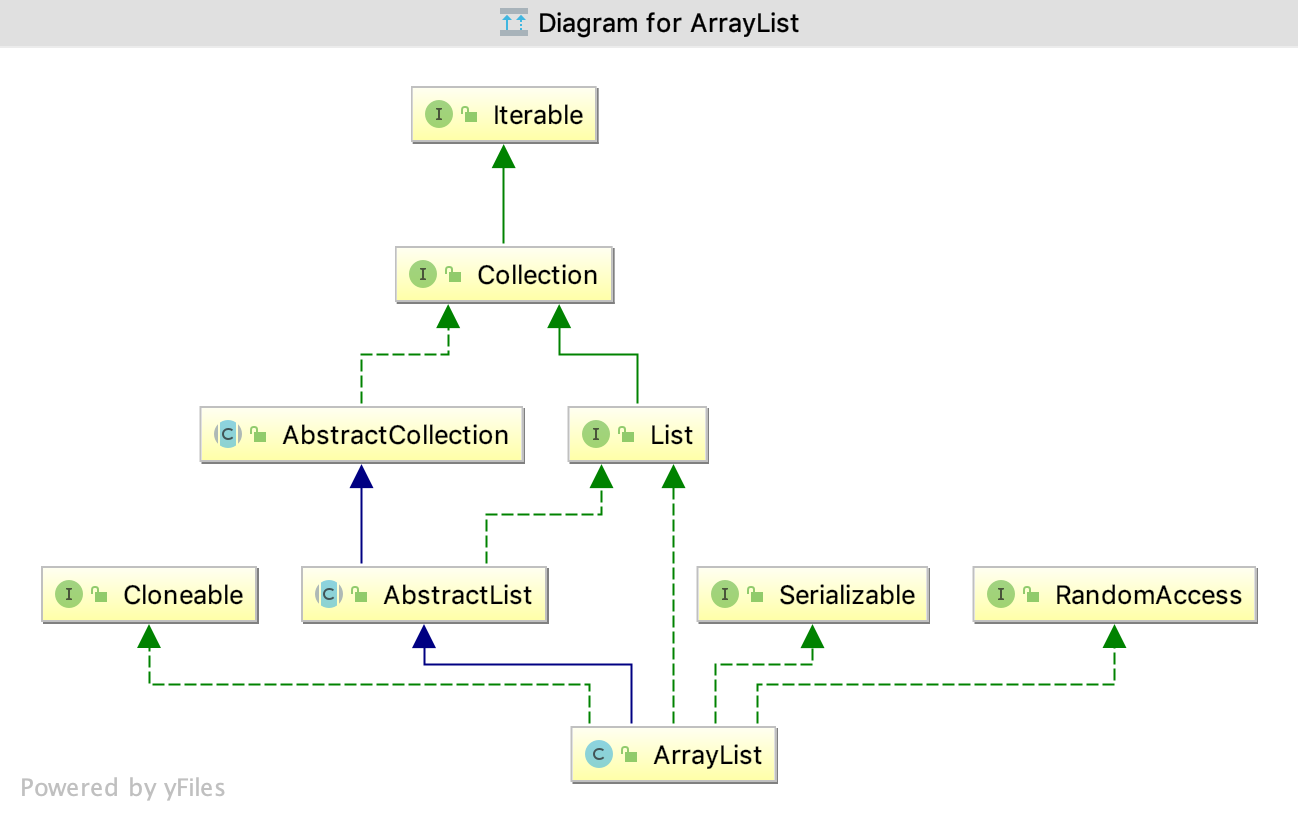
- ArrayList平时开发过程中使用最多的,是一个线程不安全的动态数组。所以性能上相对Vector好很多。
LinkedList
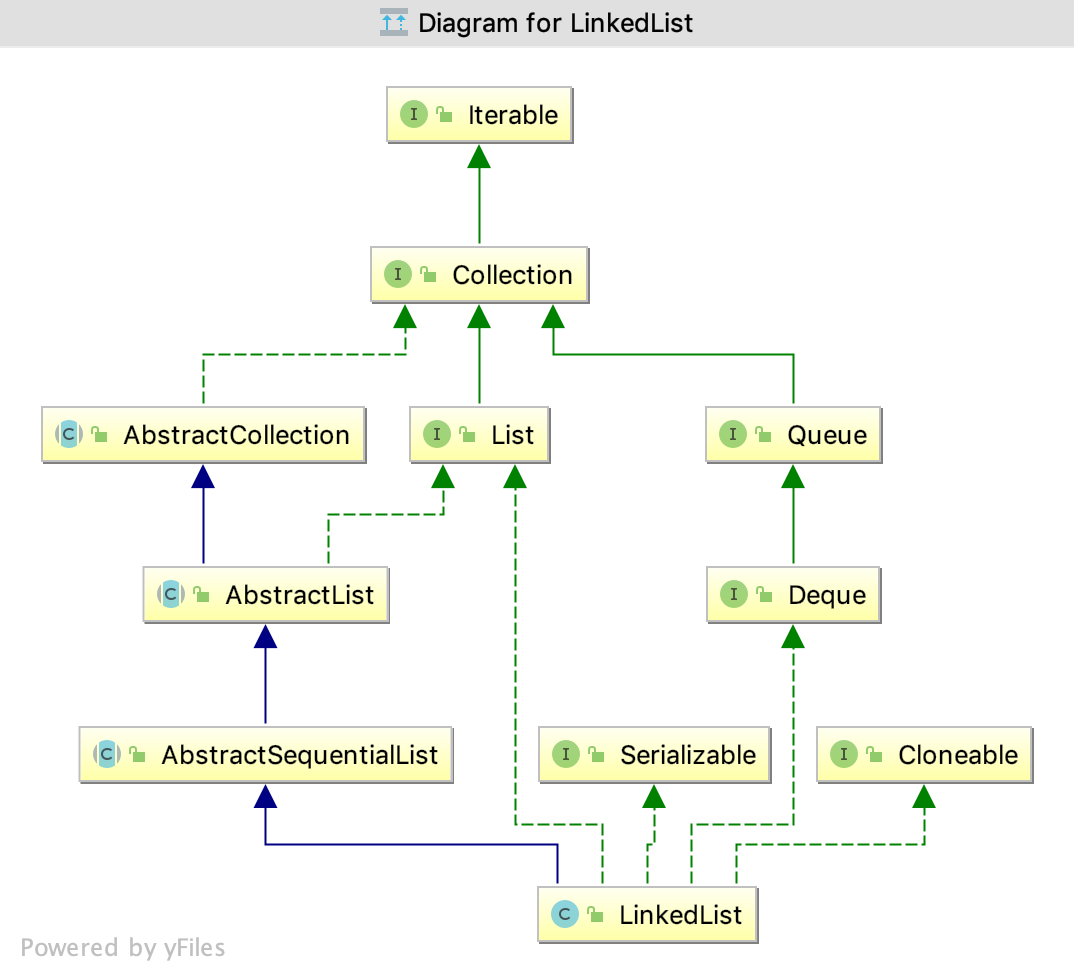
- 它是一个链表,对比ArrayList和Vector不需要扩容。但没有实现
RandomAccess接口。RandomAccess的实现,则尽量用for(int i = 0; i < size; i++) 来遍历而不要用Iterator迭代器来遍历。
ArrayList VS linkedList
Array (数组)是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的。
Array获取数据的时间复杂度是O(1),但是要删除数据却是开销很大,因为这需要重排数组中的所有数据, (因为删除数据以后, 需要把后面所有的数据前移)
1 | // 数组初始化必须指定初始化的长度, 否则报错 |
ArrayList是用一个可扩容的数组来实现的 (re-sizing array);LinkedList是用doubly-linked list来实现的。数组和链表之间最大的区别就是数组是可以随机访问的(random access)。
- 这个特点造成了在数组里可以通过下标用 O(1) 的时间拿到任何位置的数,而链表则做不到,只能从头开始逐个遍历。
ArrayList vs Vector
Vector是线程安全的,而ArrayList是线程不安全的;扩容时扩多少的区别,文邹邹的说法就是
data growth methods不同,
Vector默认是扩大至 2 倍;ArrayList默认是扩大至 1.5 倍。
- Vector 和 ArrayList 一样,也是继承自 java.util.AbstractList,底层也是用数组来实现的。
HashMap加载因子为什么是 0.75?
加载因子也叫扩容因子或负载因子,用来判断什么时候进行扩容的,假如加载因子是 0.5,HashMap 的初始化容量是 16,那么当 HashMap 中有 16*0.5=8 个元素时,HashMap 就会进行扩容。
那加载因子为什么是 0.75 而不是 0.5 或者 1.0 呢?
这其实是出于容量和性能之间平衡的结果:
当加载因子设置比较大的时候,扩容的门槛就被提高了,扩容发生的频率比较低,占用的空间会比较小,但此时发生 Hash 冲突的几率就会提升,因此需要更复杂的数据结构来存储元素,这样对元素的操作时间就会增加,运行效率也会因此降低;
而当加载因子值比较小的时候,扩容的门槛会比较低,因此会占用更多的空间,此时元素的存储就比较稀疏,发生哈希冲突的可能性就比较小,因此操作性能会比较高。
所以综合了以上情况就取了一个 0.5 到 1.0 的平均数 0.75 作为加载因子。
当有哈希冲突时,HashMap 是如何查找并确认元素的?
- 当哈希冲突时我们需要通过判断 key 值是否相等,才确认此元素是不是我们想要的元素。
为什么改 equals() 一定要改 hashCode()?
首先基于一个假设:任何两个
object的hashCode都是不同的。也就是hash function是有效的。
- 那么在这个条件下,有两个
object是相等的,那如果不重写hashCode(),算出来的哈希值都不一样,就会去到不同的buckets了,就迷失在茫茫人海中了,再也无法相认,就和equals()条件矛盾了,证毕。hashCode()决定了key放在这个桶里的编号,也就是在数组里的index;equals()是用来比较两个object是否相同的。
HashMap和HashTable的区别?
两者父类不同
HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
对外提供的接口不同
- Hashtable比HashMap多提供了elments() 和contains() 两个方法。elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。
null支持不同
Hashtable:key和value都不能为null。
HashMap:key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;可以有多个key
值对应的value为null。
线程安全不同
HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题,因此需要开发人员自己处理多线程的安全问题。
Hashtable是线程安全的,它的每个方法上都有synchronized 关键字,因此可直接用于多线程中。
虽然HashMap是线程不安全的,但是它的效率远远高于Hashtable,这样设计是合理的,因为大部分的使用场景都是单线程。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。
如何解决哈希冲突?
一般来说哈希冲突有两大类解决方式:
Separate chaining
Open addressing
Java 中采用的是第一种
Separate chaining,即在发生碰撞的那个桶后面再加一条“链”来存储。- JDK1.6 和 1.7 是用链表存储的,这样如果碰撞很多的话,就变成了在链表上的查找,worst case 就是 O(n);
- JDK 1.8 进行了优化,当链表长度较大时(超过 8),会采用红黑树来存储,这样大大提高了查找效率。
第二种方法
open addressing也是非常重要的思想,因为在真实的分布式系统里,有很多地方会用到hash的思想但又不适合用seprate chaining。- 这种方法是顺序查找,如果这个桶里已经被占了,那就按照“某种方式”继续找下一个没有被占的桶,直到找到第一个空的。
Collection vs Collections
- Collection集合接口
- Collections是工具类,提供了一些静态方法。