17年年底做的技术调研,文档好想没有写完。
gRPC
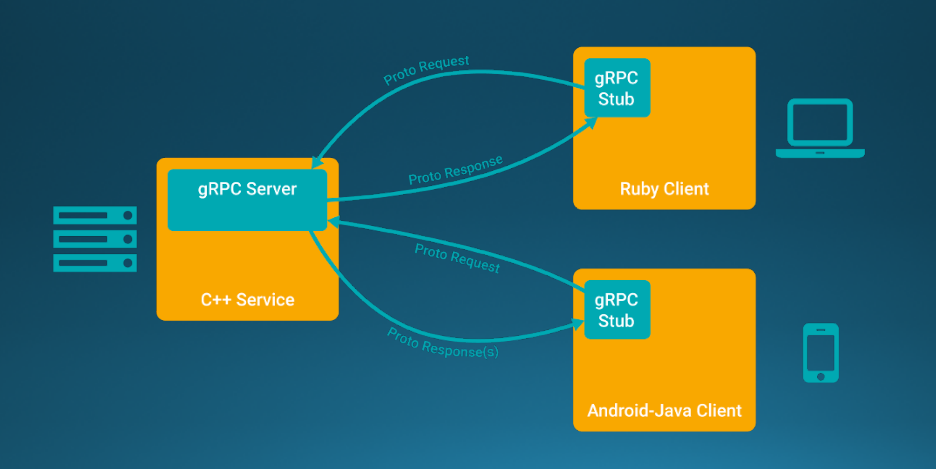
流程概念
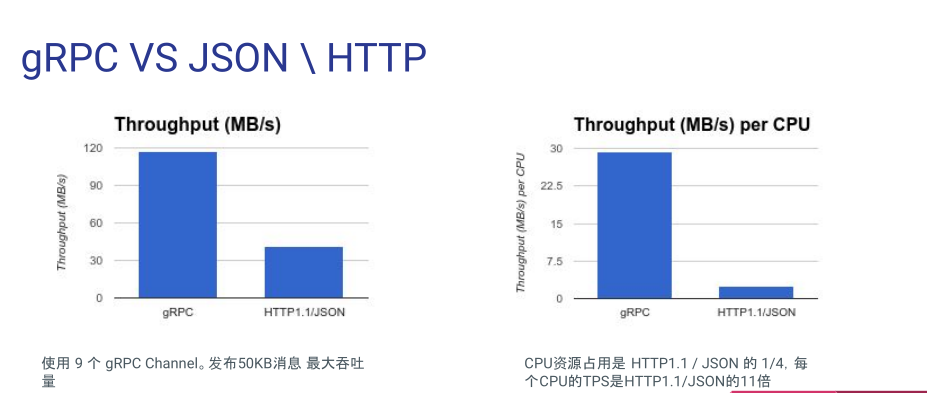
性能对比
谁在使用

ProtoBuf
Protocol Buffers 是 google 的一种数据交换的格式,它独立于语言,独立于平台。google 提供了多种语言的实现:java、c#、c++、go、PHP 和 python,每一种实现都包含了相应语言的编译器以及库文件。由于它是一种二进制的格式,比使用 xml 进行数据交换快许多。可以把它用于分布式应用之间的数据通信或者异构环境下的数据交换。作为一种效率和兼容性都很优秀的二进制数据传输格式,可以用于诸如网络传输、配置文件、数据存储等诸多领域。
至于protobuf是什么、使用场景、有什么好处,本文不做说明,这里将会为大家介绍怎么用
protobuf来定义我们的交互协议,包括.proto的语法以及如何根据proto文件生成相应的代码。本文基于proto3,读者也可以点击了解proto2
proto3语法
定义一个 Message
首先我们来定义一个 Search 请求,在这个请求里面,我们需要给服务端发送三个信息:
- query:查询条件
- page_number:你想要哪一页数据
- result_per_page:每一页有多少条数据
于是我们可以这样定义:
1 | // 指定使用proto3,如果不指定的话,编译器会使用proto2去编译 |
定义多个 message 类型
一个 proto 文件可以定义多个 message ,比如我们可以在刚才那个 proto 文件中把服务端返回的消息结构也一起定义:
1 | message SearchRequest { |
message 可以嵌套定义,比如 message 可以定义在另一个 message 内部
1 | message SearchResponse { |
定义在 message 内部的 message 可以这样使用:
1 | message SomeOtherMessage { |
定义变量类型
在刚才的例子之中,我们使用了2个标准值类型: string 和 int32,除了这些标准类型之外,变量的类型还可以是复杂类型,比如自定义的枚举和自定义的 message
这里我们把标准类型列举一下protobuf内置的标准类型以及跟各平台对应的关系:
| .proto | 说明 | Java | Python | Go |
|---|---|---|---|---|
| double | double | float | float64 | |
| float | float | float | float32 | |
| int32 | 使用变长编码,对负数编码效率低,如果你的变量可能是负数,可以使用sint32 | int | int | int32 |
| int64 | 使用变长编码,对负数编码效率低,如果你的变量可能是负数,可以使用sint64 | long | int/long | int64 |
| uint32 | 使用变长编码 | int | int/long | uint32 |
| uint64 | 使用变长编码 | long | int/long | uint64 |
| sint32 | 使用变长编码,带符号的int类型,对负数编码比int32高效 | int | int | int32 |
| sint64 | 使用变长编码,带符号的int类型,对负数编码比int64高效 | long | int/long | int64 |
| fixed32 | 4字节编码, 如果变量经常大于228 的话,会比uint32高效 | int | int | int32 |
| fixed64 | 8字节编码, 如果变量经常大于256 的话,会比uint64高效 | long | int/long | uint64 |
| sfixed32 | 4字节编码 | int | int | int32 |
| sfixed64 | 8字节编码 | long | int/long | int64 |
| bool | boolean | bool | bool | |
| string | 必须包含utf-8编码或者7-bit ASCII text | String | str/unicode | string |
| bytes | 任意的字节序列 | ByteString | str | []byte |
补充说明:
- In Java, unsigned 32-bit and 64-bit integers are represented using their signed counterparts, with the top bit simply being stored in the sign bit.
- In all cases, setting values to a field will perform type checking to make sure it is valid.
- 64-bit or unsigned 32-bit integers are always represented as long when decoded, but can be an int if an int is given when setting the field. In all cases, the value must fit in the type represented when set. See 2.
- Python strings are represented as unicode on decode but can be str if an ASCII string is given (this is subject to change).
- Integer is used on 64-bit machines and string is used on 32-bit machines.
关于标准值类型,还可以参考Scalar Value Types
如果你想了解这些数据是怎么序列化和反序列化的,可以点击 Protocol Buffer Encoding 了解更多关于protobuf编码内容。
分配Tag
每一个变量在message内都需要自定义一个唯一的数字Tag,protobuf会根据Tag从数据中查找变量对应的位置,具体原理跟protobuf的二进制数据格式有关。Tag一旦指定,以后更新协议的时候也不能修改,否则无法对旧版本兼容。
Tag的取值范围最小是1,最大是229-1,但 19000~19999 是 protobuf 预留的,用户不能使用。
虽然 Tag 的定义范围比较大,但不同 Tag 也会对 protobuf 编码带来一些影响:
- 1 ~ 15:单字节编码
- 16 ~ 2047:双字节编码
使用频率高的变量最好设置为1 ~ 15,这样可以减少编码后的数据大小,但由于Tag一旦指定不能修改,所以为了以后扩展,也记得为未来保留一些 1 ~ 15 的 Tag
指定变量规则
在 proto3 中,可以给变量指定以下两个规则:
singular:0或者1个,但不能多于1个repeated:任意数量(包括0)
当构建 message 的时候,build 数据的时候,会检测设置的数据跟规则是否匹配
在proto2中,规则为:
- required:必须有一个
- optional:0或者1个
- repeated:任意数量(包括0)
注释
用//表示注释开头,如
1 | message SearchRequest { |
保留变量不被使用
上面我们说到,一旦 Tag 指定后就不能变更,这就会带来一个问题,假如在版本1的协议中,我们有个变量:
1 | int32 number = 1; |
在版本2中,我们决定废弃对它的使用,那我们应该如何修改协议呢?注释掉它?删除掉它?如果把它删除了,后来者很可能在定义新变量的时候,使新的变量 Tag = 1 ,这样会导致协议不兼容。那有没有办法规避这个问题呢?我们可以用 reserved 关键字,当一个变量不再使用的时候,我们可以把它的变量名或 Tag 用 reserved 标注,这样,当这个 Tag 或者变量名字被重新使用的时候,编译器会报错
1 | message Foo { |
默认值
当解析 message 时,如果被编码的 message 里没有包含某些变量,那么根据类型不同,他们会有不同的默认值:
- string:默认是空的字符串
- byte:默认是空的bytes
- bool:默认为false
- numeric:默认为0
- enums:定义在第一位的枚举值,也就是0
- messages:根据生成的不同语言有不同的表现,参考generated code guide
注意,收到数据后反序列化后,对于标准值类型的数据,比如bool,如果它的值是 false,那么我们无法判断这个值是对方设置的,还是对方压根就没给这个变量设置值。
定义枚举 Enumerations
在 protobuf 中,我们也可以定义枚举,并且使用该枚举类型,比如:
1 | message SearchRequest { |
枚举定义在一个消息内部或消息外部都是可以的,如果枚举是 定义在 message 内部,而其他 message 又想使用,那么可以通过 MessageType.EnumType 的方式引用。定义枚举的时候,我们要保证第一个枚举值必须是0,枚举值不能重复,除非使用 option allow_alias = true 选项来开启别名。如:
1 | enum EnumAllowingAlias { |
枚举值的范围是32-bit integer,但因为枚举值使用变长编码,所以不推荐使用负数作为枚举值,因为这会带来效率问题。
如何引用其他 proto 文件
在proto语法中,有两种引用其他 proto 文件的方法: import 和 import public,这两者有什么区别呢?下面举个例子说明: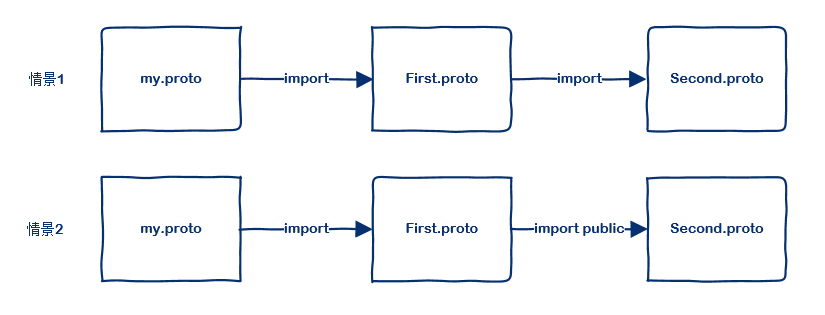
- 在情景1中, my.proto 不能使用 second.proto 中定义的内容
- 在情景2中, my.proto 可以使用 second.proto 中定义的内容
- 情景1和情景2中,my.proto 都可以使用 first.proto
- 情景1和情景2中,first.proto 都可以使用 second.proto
1 | // my.proto |
1 | // first.proto |
1 | // second.proto |
升级 proto 文件正确的姿势
升级更改 proto 需要遵循以下原则
- 不要修改任何已存在的变量的 Tag
- 如果你新增了变量,新生成的代码依然能解析旧的数据,但新增的变量将会变成默认值。相应的,新代码序列化的数据也能被旧的代码解析,但旧代码会自动忽略新增的变量。
- 废弃不用的变量用 reserved 标注
- int32、 uint32、 int64、 uint64 和 bool 是相互兼容的,这意味你可以更改这些变量的类型而不会影响兼容性
- sint32 和 sint64 是兼容的,但跟其他类型不兼容
- string 和 bytes 可以兼容,前提是他们都是UTF-8编码的数据
- fixed32 和 sfixed32 是兼容的, fixed64 和 sfixed64是兼容的
Any 的使用
Any可以让你在 proto 文件中使用未定义的类型,具体里面保存什么数据,是在上层业务代码使用的时候决定的,使用 Any 必须导入 import google/protobuf/any.proto
1 | import "google/protobuf/any.proto"; |
Oneof 的使用
Oneof 类似union,如果你的消息中有很多可选字段,而同一个时刻最多仅有其中的一个字段被设置的话,你可以使用oneof来强化这个特性并且节约存储空间,如
1 | message LoginReply { |
这样,name 和 age 都是 LoginReply 的成员,但不能给他们同时设置值(设置一个oneof字段会自动清理其他的oneof字段)。
Maps 的使用
protobuf 支持定义 map 类型的成员,如:
1 | map<key_type, value_type> map_field = N; |
- key_type:必须是string或者int
- value_type:任意类型
使用 map 要注意:
- Map 类型不能使 repeated
- Map 是无序的
- 以文本格式展示时,Map 以 key 来排序
- 如果有相同的键会导致解析失败
Packages 的使用
为了防止不同消息之间的命名冲突,你可以对特定的.proto文件提指定 package 名字。在定义消息的成员的时候,可以指定包的名字:
1 | package foo.bar; |
1 | message Foo { |
Options
Options 分为 file-level options(只能出现在最顶层,不能在消息、枚举、服务内部使用)、 message-level options(只能在消息内部使用)、field-level options(只能在变量定义时使用)
- java_package (file option):指定生成类的包名,如果没有指定此选项,将由关键字package指定包名。此选项只在生成 java 代码时有效
- java_multiple_files (file option):如果为 true, 定义在最外层的 message 、enum、service 将作为单独的类存在
- java_outer_classname (file option):指定最外层class的类名,如果不指定,将会以文件名作为类名
- optimize_for (file option):可选有 [SPEED|CODE_SIZE|LITE_RUNTIME] ,分别是效率优先、空间优先,第三个lite是兼顾效率和代码大小,但是运行时需要依赖 libprotobuf-lite
- cc_enable_arenas (file option):启动arena allocation,c++代码使用
- objc_class_prefix (file option):Objective-C使用
- deprecated (field option):提示变量已废弃、不建议使用
1 | option java_package = "com.example.foo"; |
定义 Services
这个其实和gRPC相关,详细可参考:gRPC, 这里做一个简单的介绍
要定义一个服务,你必须在你的 .proto 文件中指定 service
1 | service RouteGuide { |
然后在我们的服务中定义 rpc 方法,指定它们的请求的和响应类型。gRPC 允许你定义4种类型的 service 方法
简单RPC
客户端使用 Stub 发送请求到服务器并等待响应返回,就像平常的函数调用一样,这是一个阻塞型的调用
1 | // Obtains the feature at a given position. |
服务器端流式 RPC
客户端发送请求到服务器,拿到一个流去读取返回的消息序列。客户端读取返回的流,直到里面没有任何消息。从例子中可以看出,通过在响应类型前插入 stream 关键字,可以指定一个服务器端的流方法
1 | // Obtains the Features available within the given Rectangle. Results are |
客户端流式 RPC
客户端写入一个消息序列并将其发送到服务器,同样也是使用流。一旦客户端完成写入消息,它等待服务器完成读取返回它的响应。通过在请求类型前指定 stream 关键字来指定一个客户端的流方法
1 | // Accepts a stream of Points on a route being traversed, returning a |
双向流式 RPC
双方使用读写流去发送一个消息序列。两个流独立操作,因此客户端和服务器可以以任意喜欢的顺序读写:比如, 服务器可以在写入响应前等待接收所有的客户端消息,或者可以交替的读取和写入消息,或者其他读写的组合。每个流中的消息顺序被预留。你可以通过在请求和响应前加 stream 关键字去制定方法的类型
1 | // Accepts a stream of RouteNotes sent while a route is being traversed, |
代码生成
使用 protoc 工具可以把编写好的 proto 文件“编译”为Java, Python, C++, Go, Ruby, JavaNano, Objective-C,或C#代码, protoc 可以从点击这里进行下载。protoc 的使用方式如下:
GitHub: tags地址 https://github.com/protocolbuffers/protobuf/tags
1 | protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR --go_out=DST_DIR --ruby_out=DST_DIR --javanano_out=DST_DIR --objc_out=DST_DIR --csharp_out=DST_DIR path/to/file.proto1 |
参数说明:
- IMPORT_PATH:指定 proto 文件的路径,如果没有指定, protoc 会从当前目录搜索对应的 proto 文件,如果有多个路径,那么可以指定多次
--proto_path - 指定各语言代码的输出路径
- –cpp_out:生成c++代码
- java_out :生成java代码
- python_out :生成python代码
- go_out :生成go代码
- ruby_out :生成ruby代码
- javanano_out :适合运行在有资源限制的平台(如Android)的java代码
- objc_out :生成 Objective-C代码
- csharp_out :生成C#代码
- php_out :生成PHP代码