本章是整理知识内容,为强化知识长期更新。
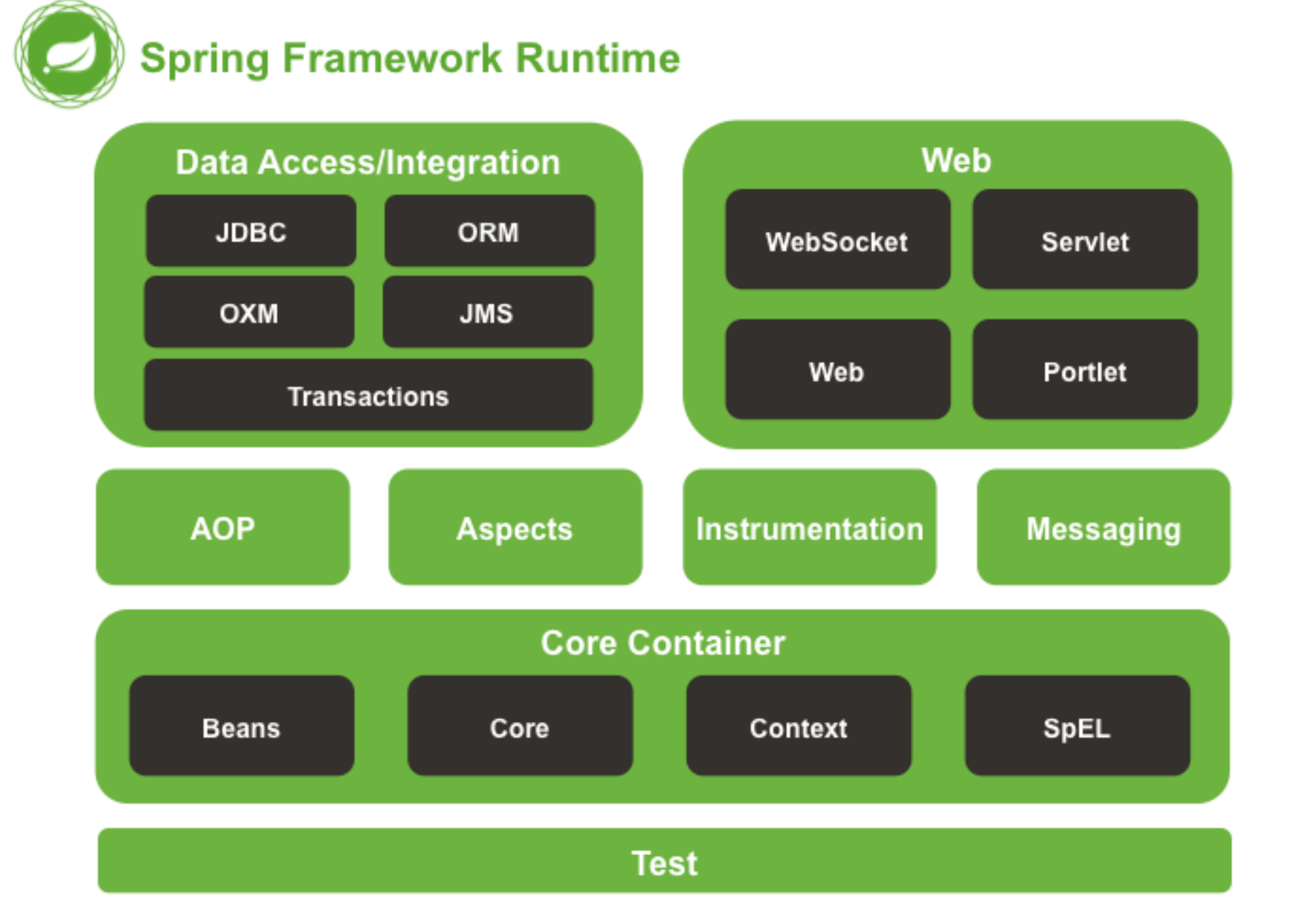
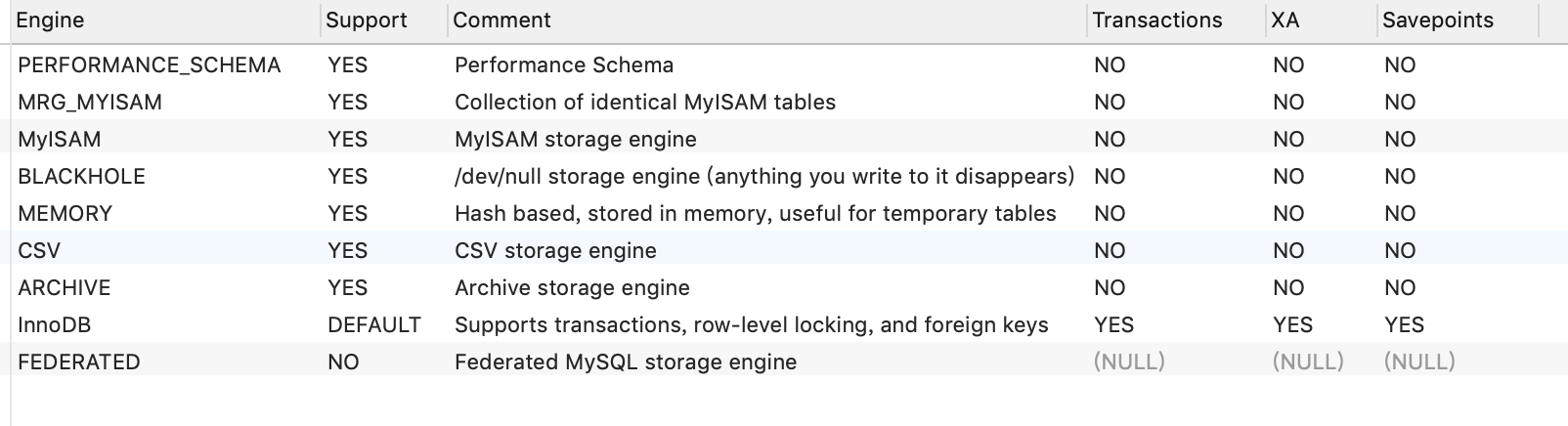
整体架构
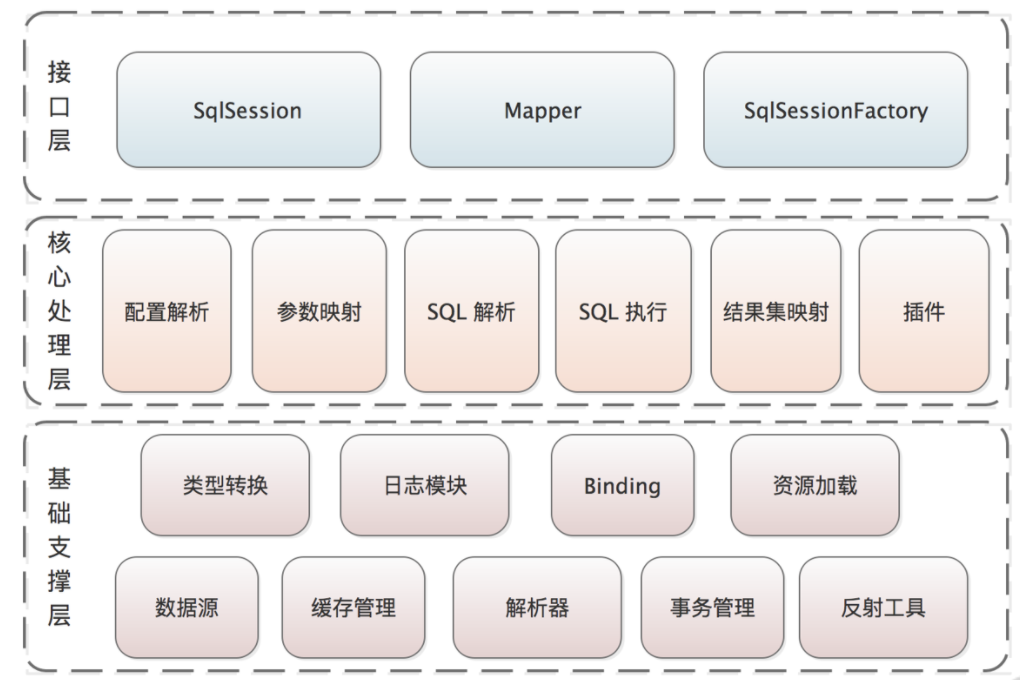
基础层
处理层
接口层
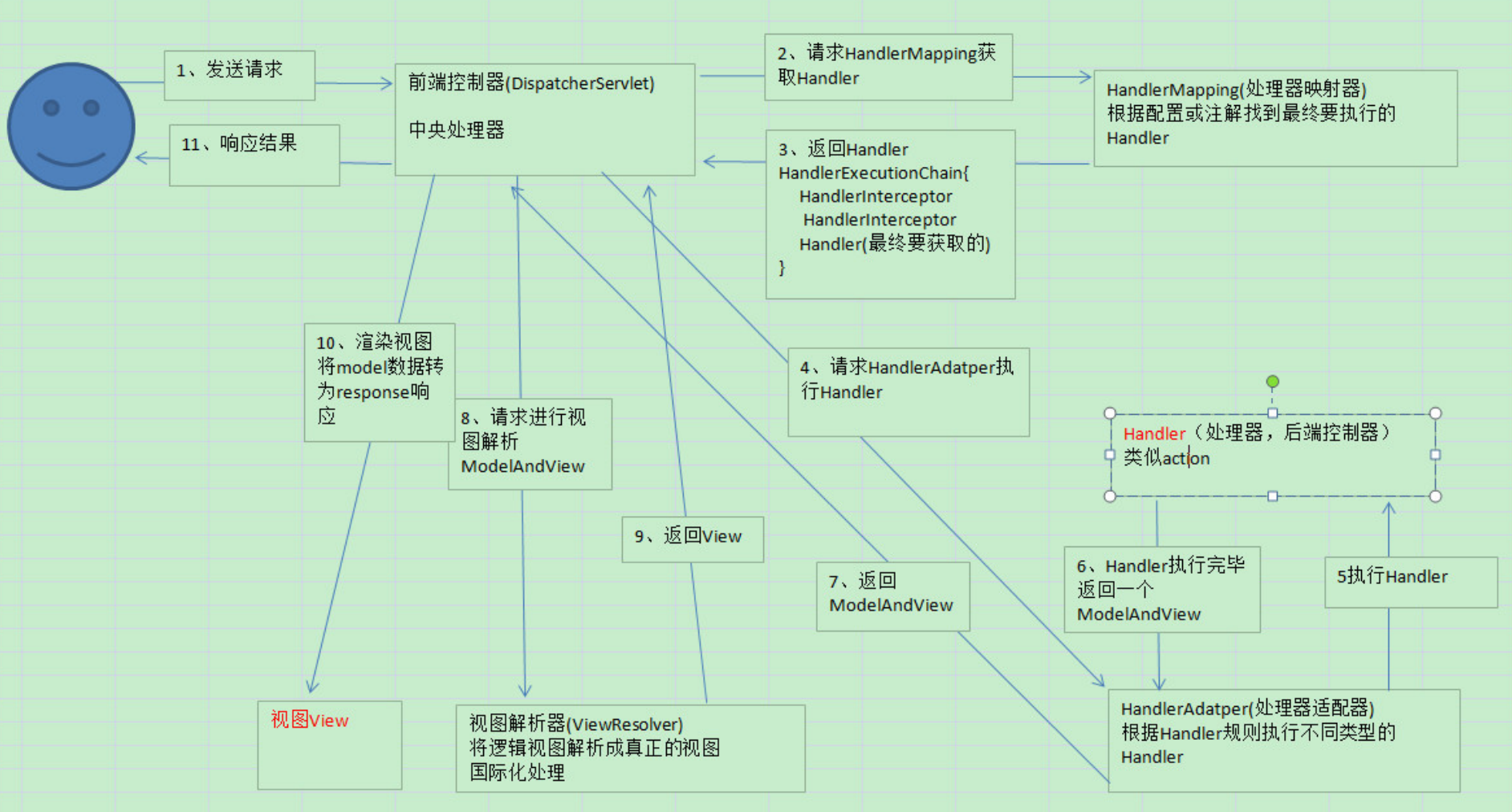
Mybatis执行流程
- 获取sqlSessionFactory对象:解析文件的每一个信息保存在Configuration中,返回包含Configuration的DefaultSqlSession;注意:MappedStatement:代表一个增删改查的详细信息。
- 获取sqlSession对象,返回一个DefaultSQlSession对象,包含Executor和Configuration;这一步会创建Executor对象;
- 获取接口的代理对象(MapperProxy),getMapper,使用MapperProxyFactory创建一个MapperProxy的代理对象。
Mybatis拦截器
代理对象里面包含了,DefaultSqlSession(Executor)
- 执行增删改查方法。
- 调用DefaultSqlSession的增删改查(Executor)
- 创建一个StatementHandler对象、且同时创建出ParameterHandler和ResultSetHandler。
- 调用StatementHandler预编译参数以及设置参数值;使用ParameterHandler来给sql设置参数
- 调用StatementHandler的增删改查方法;
- ResultSetHandler封装结果
- MyBatis 拦截签名 拦截器签名是一个名为 @Intercepts 的注解,该注解中可以通过 @Signature 配置多个签名。@Signature 注解中则包含三个属性
- type: 拦截器需要拦截的接口,有 4 个可选项,分别是:Executor、ParameterHandler、ResultSetHandler 以及 StatementHandler。
- method: 拦截器所拦截接口中的方法名,也就是前面四个接口中的方法名,接口和方法要对应上。
- args: 拦截器所拦截方法的参数类型,通过方法名和参数类型可以锁定唯一一个方法。
- 被拦截的对象
- org.apache.ibatis.executor.Executor
- org.apache.ibatis.executor.statement.StatementHandler
- org.apache.ibatis.executor.statement.ParameterHandler
- org.apache.ibatis.executor.resultset.ResultSetHandler
- Executor
- update:该方法会在所有的 INSERT、 UPDATE、 DELETE 执行时被调用,如果想要拦截这些操作,可以通过该方法实现。
- query:该方法会在 SELECT 查询方法执行时被调用,方法参数携带了很多有用的信息,如果需要获取,可以通过该方法实现。
- queryCursor:当 SELECT 的返回类型是 Cursor 时,该方法会被调用。
- flushStatements:当 SqlSession 方法调用 flushStatements 方法或执行的接口方法中带有 @Flush 注解时该方法会被触发。
- commit:当 SqlSession 方法调用 commit 方法时该方法会被触发。
- rollback:当 SqlSession 方法调用 rollback 方法时该方法会被触发。
- getTransaction:当 SqlSession 方法获取数据库连接时该方法会被触发。
- close:该方法在懒加载获取新的 Executor 后会被触发。
- isClosed:该方法在懒加载执行查询前会被触发。
- StatementHandler
- prepare:该方法在数据库执行前被触发。
- parameterize:该方法在 prepare 方法之后执行,用来处理参数信息。
- batch:如果 MyBatis 的全剧配置中配置了 defaultExecutorType=”BATCH”,执行数据操作时该方法会被调用。
- update:更新操作时该方法会被触发。
- query:该方法在 SELECT 方法执行时会被触发。
- queryCursor:该方法在 SELECT 方法执行时,并且返回值为 Cursor 时会被触发。
- ParameterHandler
- getParameterObject:在执行存储过程处理出参的时候该方法会被触发。
- setParameters:设置 SQL 参数时该方法会被触发。
- ResultSetHandler
- handleResultSets:该方法会在所有的查询方法中被触发(除去返回值类型为 Cursor
的查询方法),一般来说,如果我们想对查询结果进行二次处理,可以通过拦截该方法实现。 - handleCursorResultSets:当查询方法的返回值类型为 Cursor
时,该方法会被触发。 - handleOutputParameters:使用存储过程处理出参的时候该方法会被调用。
- handleResultSets:该方法会在所有的查询方法中被触发(除去返回值类型为 Cursor
MyBatis插件
MyBatis 将插件单独分离出一个模块,位于 org.apache.ibatis.plugin 包中,在该模块中主要使用了两种设计模式:代理模式和责任链模式。
插件接口
org.apache.ibatis.plugin.Interceptor
intercept:它将直接覆盖你所拦截的对象,有个参数Invocation对象,通过该对象,可以反射调度原来对象的方法;
plugin:target是被拦截的对象,它的作用是给被拦截对象生成一个代理对象;
setProperties:允许在plugin元素中配置所需参数,该方法在插件初始化的时候会被调用一次;
MyBatis允许我们自定义 Interceptor 拦截 SQL 语句执行过程中的某些关键逻辑,允许拦截的方法有:Executor 类中的 update()、query()、flushStatements()、commit()、rollback()、getTransaction()、close()、isClosed()方法,ParameterHandler 中的 setParameters()、getParameterObject() 方法,ResultSetHandler中的 handleOutputParameters()、handleResultSets()方法,以及StatementHandler 中的parameterize()、prepare()、batch()、update()、query()方法。
MyBatis中的设计模式
- 工厂模式
- 工厂模式在 MyBatis 中的典型代表是 SqlSessionFactory。
- SqlSession 是 MyBatis 中的重要 Java 接口,可以通过该接口来执行 SQL 命令、获取映射器示例和管理事务,而 SqlSessionFactory 正是用来产生 SqlSession 对象的,所以它在 MyBatis 中是比较核心的接口之一。
- 工厂模式应用解析:SqlSessionFactory 是一个接口类,它的子类 DefaultSqlSessionFactory 有一个 openSession(ExecutorType execType) 的方法,其中使用了工厂模式。
- 建造者模式
- MyBatis 中的典型代表是 SqlSessionFactoryBuilder。
- 普通的对象都是通过 new 关键字直接创建的,但是如果创建对象需要的构造参数很多,且不能保证每个参数都是正确的或者不能一次性得到构建所需的所有参数,那么就需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建交给构建类,这样可以简化对象的构建,也可以达到分步构建对象的目的,而 SqlSessionFactoryBuilder 的构建过程正是如此。
- 在 SqlSessionFactoryBuilder 中构建 SqlSessionFactory 对象的过程是这样的,首先需要通过 XMLConfigBuilder 对象读取并解析 XML 的配置文件,然后再将读取到的配置信息存入到 Configuration 类中,然后再通过 build 方法生成我们需要的 DefaultSqlSessionFactory 对象。
1 | public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { |
- 单例模式
- 单例模式在 MyBatis 中的典型代表是 ErrorContext。
- 使用 private 修饰的 ThreadLocal 来保证每个线程拥有一个 ErrorContext 对象,在调用 instance() 方法时再从 ThreadLocal 中获取此单例对象。
1 | public class ErrorContext { |
适配器模式
- MyBatis 中的典型代表是 Log。
- SLF4J
- Apache Commons Logging
- Log4j 2
- Log4j
- JDK logging
- MyBatis 中的典型代表是 Log。
代理模式
- 代理模式在 MyBatis 中的典型代表是 MapperProxyFactory。
模版方法模式
- 模板方法在 MyBatis 中的典型代表是 BaseExecutor。
装饰器模式
- 装饰器模式在 MyBatis 中的典型代表是 Cache。
Mybatis一些疑问
#{} 于 ${}
使用#{}可以有效的防止SQL注入,提高系统安全性。
- #{}是预编译,${}是字符串替换。
- Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
- Mybatis在处理${}时,就是把${}替换成变量的值。
MyBatis Dao 接口的工作原理
- Dao 接口的全限定名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中 Mapper 的 Statement 的 id 值,接口方法内的参数,就是传递给 SQL 的参数。Mapper 接口是没有实现类的,当调用接口方法时,接口全限定名 + 方法名拼接字符串作为 key 值,可唯一定位一个 MapperStatement。在 MyBatis 中,每一个 select、insert、update、delete 标签,都会被解析为一个 MapperStatement 对象。
Dao 接口里的方法可以重载吗
- Mapper 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Mapper 接口生成代理对象 proxy,代理对象会拦截接口方法,转而执行 MapperStatement 所代表的 SQL,然后将 SQL 执行结果返回。所以是不能重载的