本章是整理知识内容,为强化知识长期更新。
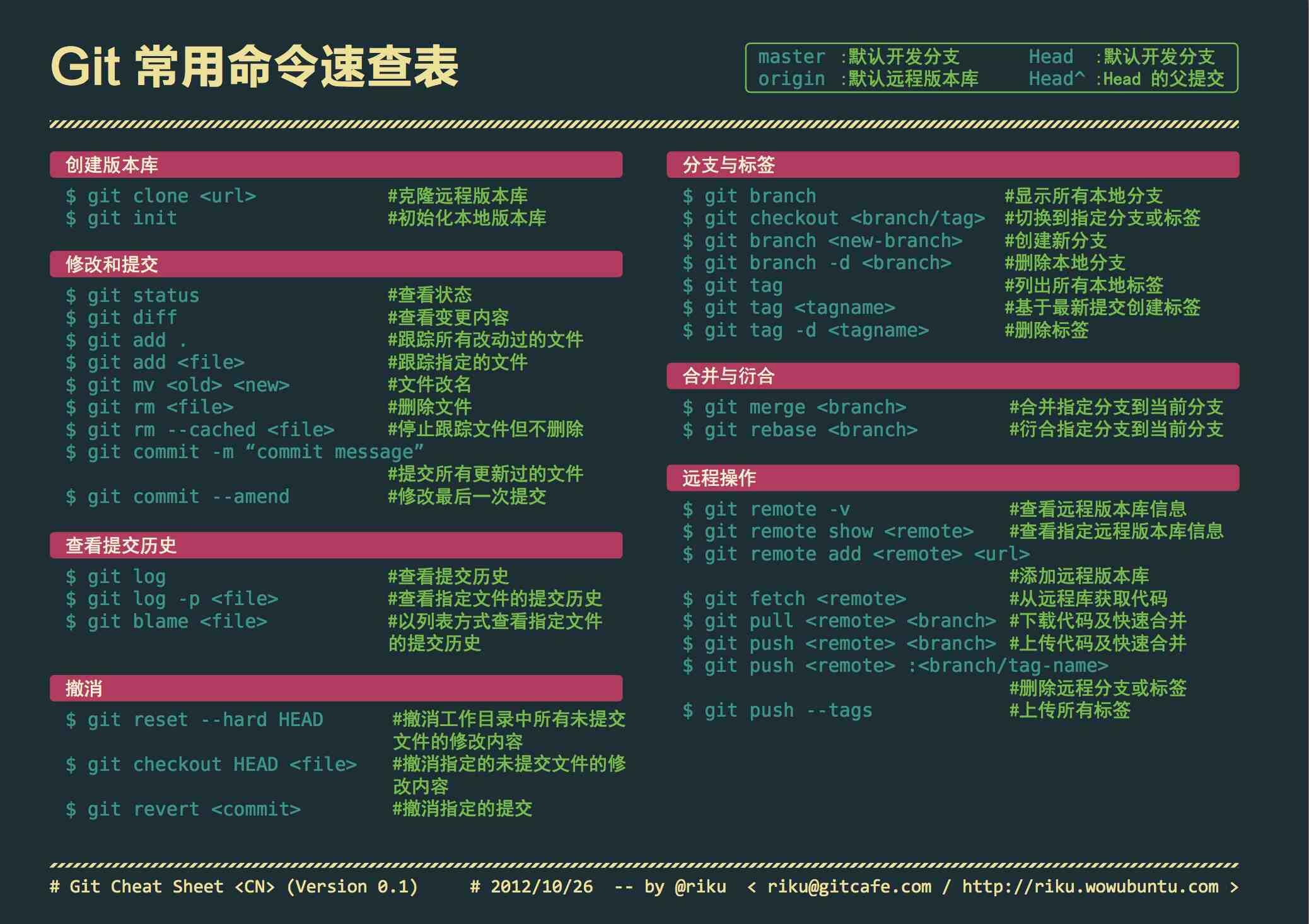
Git速度查询表
下面是常用 的Git 命令清单。几个专用名词的译名如下:
Workspace:工作区
Index / Stage:暂存区
Repository:仓库区(或本地仓库)
Remote:远程仓库
最小配置
为什么要最小配置,每次提交代码需要告诉git。所以需要简单设置下user信息。
1 2 git config --global user.name 'your name' git config --global user.email 'your email'
这里需要注意config的三个作用域
1 2 3 git config --local git config --global git config --system
我们一般只会使用local 和 global这两个配置。当我们配置好user.name user.email之后,我们可以检查下配置信息。
1 2 3 git config --list --local git config --list --global git config --list --system
创建一个本地仓库
一般来说git仓库有两种情况,一种是没有仓库,另外一种就是已经有仓库了。这里对第一种情况演示,因为工作中习惯在web上创建仓库。这里还是了解下。
创建一个README文件。
这里需要说明下,本地仓库创建完成后需要与远程仓库进行管理。
1 git remote add origin github.com:yourname/git_learning.git # 这里的yourname 是你的git账号
建议手动去github上面创建一个叫git_learning的仓库。上面的命令就是做下关联。
1 2 3 git add . git commit -m "upload file" git push origin mastet
可控一个远程仓库 1 2 git clone www.**/**.git
文件追踪
有些时候不想提交部分文件,但是git add .的时候添加进去了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # git add [file] [file] # git add [dir] # git add . # git rm -r --cached . ## 不删除本地文件 git rm -r --f . ## 删除本地文件 # git rm --cached readme1.txt ## 删除readme1.txt的跟踪,并保留在本地。 git rm --f readme1.txt ## 删除readme1.txt的跟踪,并且删除本地文件s
提交仓库
如果发现message写错了,可以修改下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 git commit --amend git commit [file1] [file2] ... -m [message] git commit -m git commit -am git push -f origin master git push origin : xxxx git push origin --delete xxxx
如果想修改以往的commit的message。注意是不连续的commit。
首先查看log 里面的信息,然后获取commitid进行合并