本篇幅只是回顾使用eureka的时候如何钉钉告警。
Eureka钉钉告警
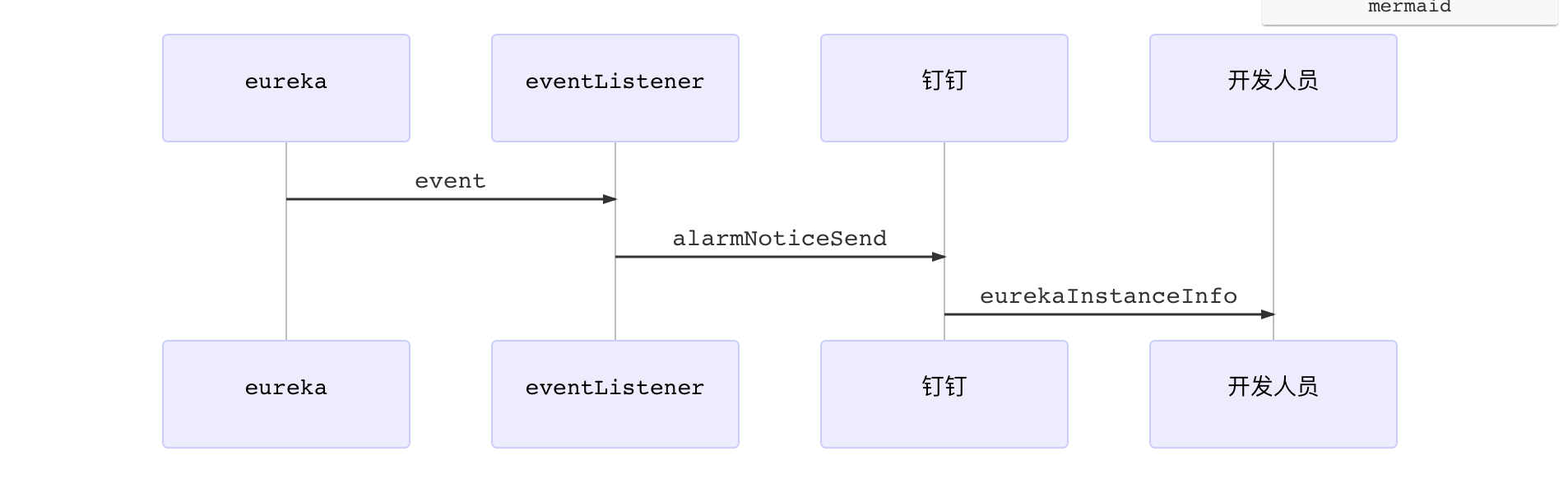
1 | sequenceDiagram |
- 实例图
关键代码
1 |
|
- 效果如下
1 | 告警通知 服务下线 |
- eureka查看源码得知有五个事件。
1 | EurekaServerStartedEvent - Eureka服务端启动事件 |
这里就比较简单了。
本篇幅只是回顾使用eureka的时候如何钉钉告警。
1 | sequenceDiagram |
1 |
|
1 | 告警通知 服务下线 |
1 | EurekaServerStartedEvent - Eureka服务端启动事件 |
这里就比较简单了。
本篇幅只是回顾使用钉钉做异常告警需要那些关键业务信息。
事情要从我入职上家公司说起,进入公司后把线上项目clone下来大致看了下。代码风格过于滞后、编码风格混乱。进入公司第一周就出现了线上故障,嗯。我去线上检查日志,emmmm竟然没有日志输出。这次故障是由客户反馈来的。当时我非常吃惊,大伙好像很淡定的样子,习以为常了?
想到当初面试的时候和总监的谈话,主要是带领团队落地微服务架构,看来必须大刀阔斧了。
首先想到的时候改进日志输出、定义全局异常级别,根据异常级别输出日志。
1 | sequenceDiagram |
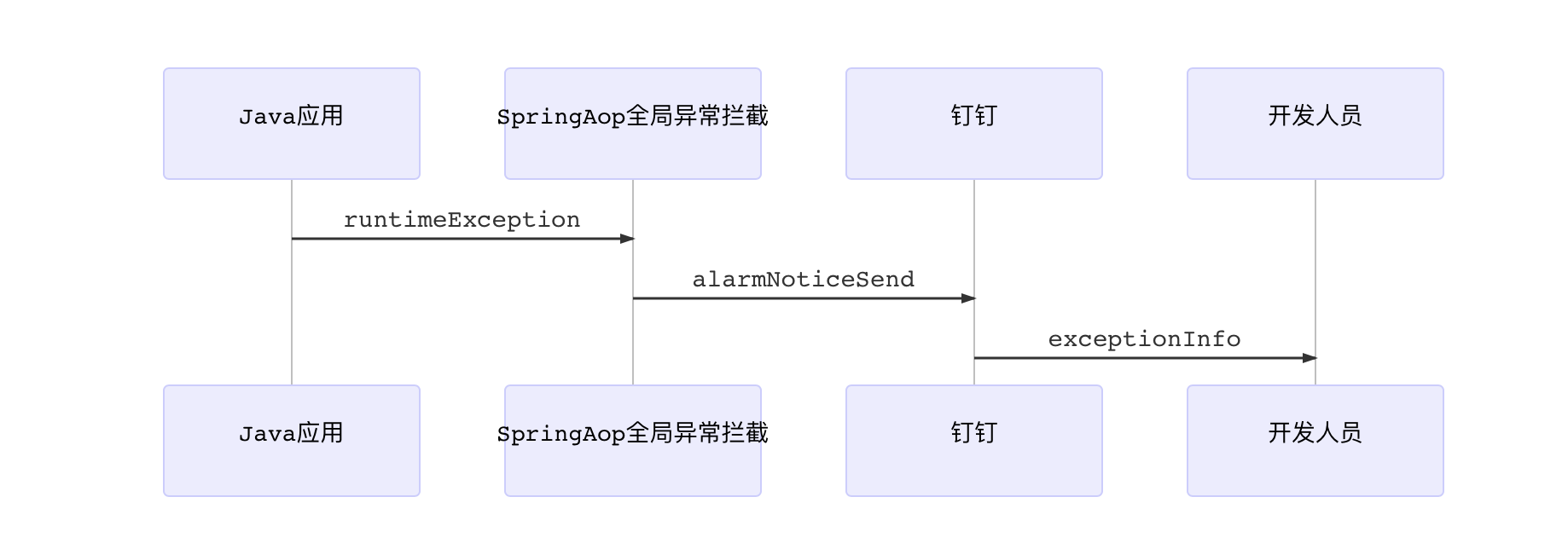
我们需要从钉钉里面看到那些异常信息呢?这是当时输出到钉钉的信息。通过编写全局拦截器,在公共基础项目里面添加了aop全局拦截。刚开始上线的时候钉钉一天动不动就几千个异常告警。刚开始大伙都很紧张,过了个把月大伙已经又麻木了。
1 | 告警信息 |
明显这样是不够够的,前端有安卓、ios、微信小程序、web、快应用。太多前端项目了,后端需要识别出是哪里的项目出的问题。于是又改进了一次。邀请前端开发人员在HttpHeader里面增加额外参数。为了做流量区分也增加了一些参数。
1 | { |
通过上面的改进告警信息完善很多。
1 | 告警信息 |
1 | sequenceDiagram |
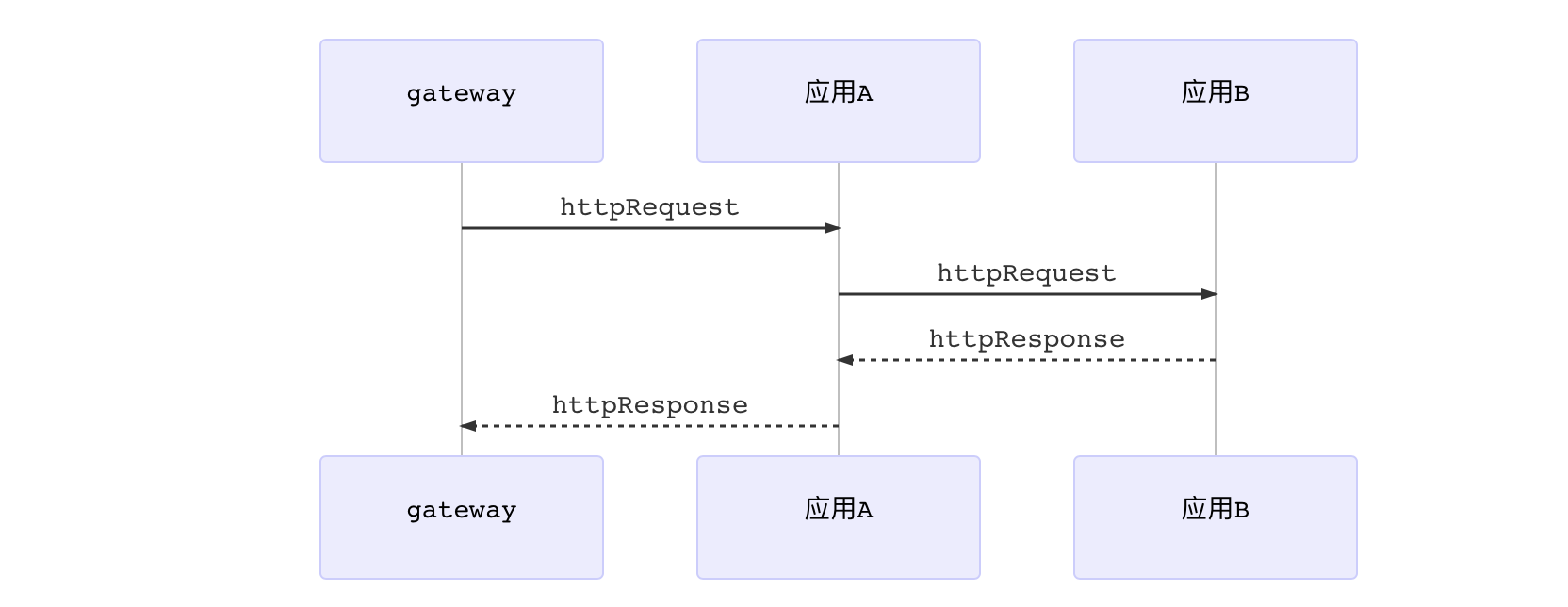
当调用链多的时候定位问题就有点麻烦,比如应用a调用应用b。应用b执行了异常信息直接抛出了告警信息。但是spring cloud http rpc默认是不会吧请求参数传递到后面的服务中,需要我们做下简单的扩展。
1 | /** |
简单的异常钉钉告警就到这里结束了。
本章是整理知识内容,为强化知识长期更新。
JVM 全称 Java Virtual Machine,也就是我们耳熟能详的 Java 虚拟机。JVM 会翻译执行 Java 字节码,然后调用真正的操作系统函数,这些操作系统函数是与平台息息相关的。
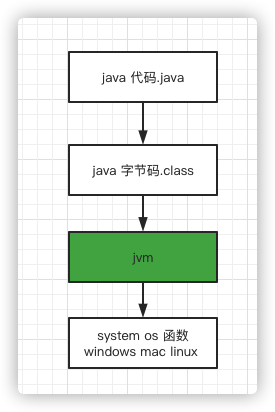
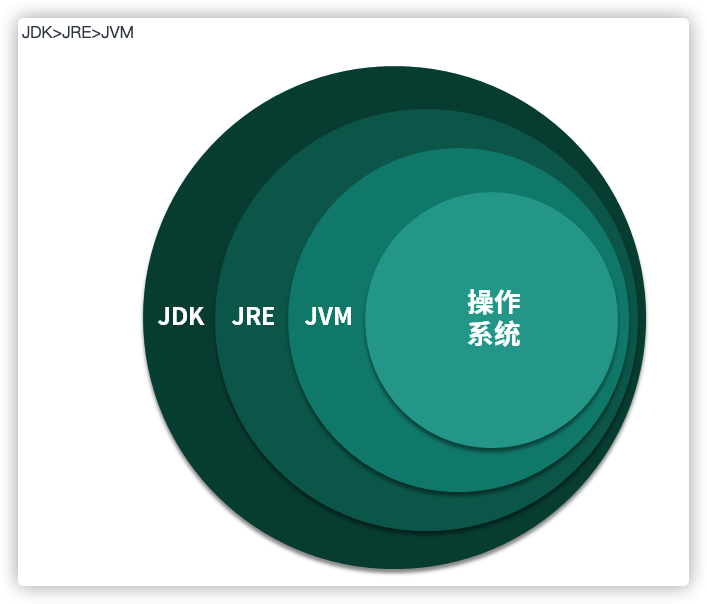
对于 Java 开发者来说,虚拟机、字节码就是其底层知识。
Java Byte由单字节byte的指令组成,理论上最多支持256个操作码。实际上只使用了200个左右操作码。
这里采用xxd xx.java
1 |
|
1 | ➜ jvm git:(master) ✗ javac Testing.java |
javapjavap能对给定的class文件提供的字节代码进行反编译
1 | javap <options> <classes> |
1 | javap -c -s -v Testing |
jclasslib is a bytecode viewer for Java class files

堆(Java Heap) 也叫 Java 堆或者是 GC 堆,它是一个线程共享的内存区域,也是 JVM 中占用内存最大的一块区域,Java 中所有的对象都存储在这里。
存储的是我们new来的对象,不存放基本类型和对象引用。
由于创建了大量的对象,垃圾回收器主要工作在这块区域。
线程共享区域,因此是线程不安全的。
能够发生内存溢出,主要有OutOfMemoryError和StackOverflowError。
那么什么时候发生OutOfMemoryError,什么时候发生StackOverflowError?虚拟机在扩展栈时无法申请到足够的内存空间,将抛出OutOfMemoryError异常,线程请求的栈深度超过虚拟机所允许的最大深度,将抛出StackOverflowError异常。
Java堆区还可以划分为新生代和老年代,新生代又可以进一步划分为Eden区、Survivor 1区、Survivor 2区。具体比例参数的话,可以看一下下面这张图。

Minor GC 发生在新生代,而 Full GC 发生在老年代。
大部分新生成的对象都是在 Eden 区,Eden 区满了之后便没有内存给新对象使用,Eden 区便会 Minor GC 回收无用内存,剩下的存活对象便会转移到 Survivor 区。
从 Eden 区存活下来的对象首先会被复制到 From 区,当 From 区满时,此时还存活的对象会被转移到 To 区,经历了多次的 Minor GC 后,还存活的对象就会被复制到老年代,老年代的 GC 一般叫作 FullGC 或者 MajorGC。

1 | java.lang.OutOfMemoryError: Java heap space |
Java 虚拟机的堆内存设置不够,可以通过-Xms、-Xmx来调整
代码中创建了大量大对象,并且长时间不能被垃圾回收器收集
内存加载的数据量太大:一次性从数据库取太多数据
集合类中有对对象的引用,使用后未清空,GC不能进行回收
代码中存在循环产生过多的重复对象
线程私有区域,每一个线程都有独享一个虚拟机栈,因此这是线程安全的区域。
存放基本数据类型以及对象的引用。
每一个方法执行的时候会在虚拟机栈中创建一个相应栈帧,方法执行完毕后该栈帧就会被销毁。方法栈帧是以先进后出的方式虚拟机栈的。
每一个栈帧又可以划分为局部变量表、操作数栈、动态链接、方法出口以及额外的附加信息。
本地方法栈(Native Method Stacks)与虚拟机栈类似,它是线程独享的,并且作用也和虚拟机栈类似。只不过虚拟机栈是为虚拟机中执行的 Java 方法服务的,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
JVM 的执行流程是,首先先把 Java 代码(.java)转化成字节码(.class),然后通过类加载器将字节码加载到内存中,所谓的内存也就是我们上面介绍的运行时数据区,但字节码并不是可以直接交给操作系统执行的机器码,而是一套 JVM 的指令集。这个时候需要使用特定的命令解析器也就是我们俗称的执行引擎(Execution Engine)将字节码翻译成可以被底层操作系统执行的指令再去执行,这样就实现了整个 Java 程序的运行,这也是 JVM 的整体执行流程。
符号引用和直接引用有一个重要的区别:使用符号引用时被引用的目标不一定已经加载到内存中;而使用直接引用时,引用的目标必定已经存在虚拟机的内存中了。
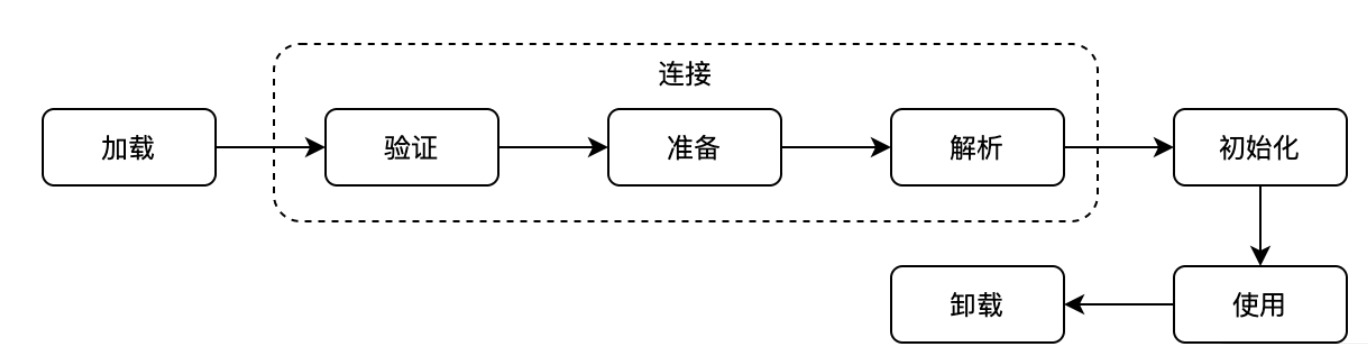
此阶段用于查到相应的类(通过类名进行查找)并将此类的字节流转换为方法区运行时的数据结构,然后再在内存中生成一个能代表此类的 java.lang.Class 对象,作为其他数据访问的入口。
此步骤主要是为了验证字节码的安全性,如果不做安全校验的话可能会载入非安全或有错误的字节码,从而导致系统崩溃,它是 JVM 自我保护的一项重要举措。
此阶段是用来初始化并为类中定义的静态变量分配内存的,这些静态变量会被分配到方法区上。这些变量所使用的内存都将在方法区(<Jdk1.8)元数据区(>=Jdk1.8)中进行分配。这时候进行内存分配的仅包括类变量,而不包括实例变量,实例变量将会在对象实例化的时候随对象一起分配在Java堆中。
此阶段主要是用来解析类、接口、字段及方法的,解析时会把符号引用替换成直接引用。
所谓的符号引用是指以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可;而直接引用是可以直接指向目标的指针、相对偏移量或者是一个能间接定位到目标的句柄。
符号引用和直接引用有一个重要的区别:使用符号引用时被引用的目标不一定已经加载到内存中;而使用直接引用时,引用的目标必定已经存在虚拟机的内存中了。
初始化阶段 JVM 就正式开始执行类中编写的 Java 业务代码了。到这一步骤之后,类的加载过程就算正式完成了。
工作中可能出现一个bug修复多次调教或者开发过程中需要临时保存代码到分支上的操作。但是合并主分支的时候不希望把过多的提交记录信息展示出来。这里就需要用到git rebase 命名。
使用git rebase 合并多条commit
1 | git log --oneline |

2.选中一个commit id作为合并到对象,从上至下按照最新提交的记录排序。这里可以选中第三条记录。
1 | git rebase -i 7893ade |
1 | # 命令: |
:wq保存1 | pick a755a10 完善单元测试 |
1 | git push -f origin branch |
rm -rf .git/rebase-mergegit log --onelineOpenResty(又称:ngx_openresty) 是一个基于 NGINX 的可伸缩的 Web 平台,由中国人章亦春发起,提供了很多高质量的第三方模块。OpenResty 是一个强大的 Web 应用服务器
1 | yum install yum-utils |
1 | yum-config-manager --add-repo https://openresty.org/package/rhel/openresty.repo |
1 | yum install -y openresty |
1 | systemctl start openresty |

1 | yum install -y openresty-resty |
1 | /usr/local/openresty/bin/openresty -V |